Google Colaboratory
Czy słyszałe(a)ś o notatniku Jupyter? Jeśli nie, możesz przeczytać ten artykuł by dowiedzieć się czym jest ten projekt i jak go używać. Notatnik Jupyter integruje kod i jego dane wyjściowe w jednym dokumencie, który łączy wizualizacje, opis, równania matematyczne i inne multimedia. Jest to dokument, w którym można uruchamiać kod, wyświetlać dane wyjściowe, a także dodawać objaśnienia, formuły, wykresy i sprawić, że praca będzie bardziej przejrzysta, zrozumiała, powtarzalna i udostępniana. Sam notatnik pobierasz np. jako pakiet Python i po uruchomieniu serwisu masz dostęp do prostego serwisu web w którym tworzysz i zarządzasz swoimi notatnikami. Lokalnie.
Wyobraź sobie że jest jednak znacznie wygodniejsze środowisko by tworzyć notatniki zawierające szczegóły twoich projektów w języku Python. Środowisko gotowe do użycia, zawierające wszystko czego potrzebujesz bez tracenia czasu na instalację, pobierania wymaganych modułów i pakietów. Tym gotowym serwisem jest Google Colaboratory - w skócie Google Colab.
Co to jest Colaboratory?
Colaboratory (czyli w skrócie „Colab”) to usługa opracowana przez Google Research. Colab umożliwia każdemu użytkownikowi pisanie i uruchamianie w przeglądarce dowolnego kodu Python. Usługa ta nadaje się zwłaszcza do analizy danych, 'machine learning' i nauki. Od strony technicznej Colab to hostowana usługa notatników Jupyter, do której używania nie trzeba niczego konfigurować. Zapewnia ona bezpłatny dostęp do zasobów obliczeniowych obejmujących m.in. układy GPU.

Tech Trends 2022
The beginning of the year is always the time when the Internet is full of predictions of what technologies will dominate the next year and other Paulo Coelho’s hints what really matters in life. Here comes our top four:
Small businesses can do more now thanks to software
Since the software "automates", if the software "analyzes" and "makes decisions," you don't need a human to perform a large number of these tasks. So smaller companies can act like larger ones. They can afford it. An organization of several people can fulfill all the functions of large companies. The power of small businesses is particularly evident in the technology sectors - when small meets large, small almost always wins. Now, thanks to the software, we will see it more often in other industries [read more].
Knowledge Even More Pricey
Someday, we will be able to write an AI that can actually think and be creative. It will be able to learn and extend itself beyond its current programming…. Stanislaw Lem would have written.
However, the software is made by people. Today, creating IT solutions means putting together a puzzle - a relatively short list of functions and algorithms creates the most complex system. But to put these puzzles into a meaningful picture, you need knowledge. Therefore, skills come at a higher price than the software itself. The computer programs make a difference not because they are easy, but because they are hard to make.
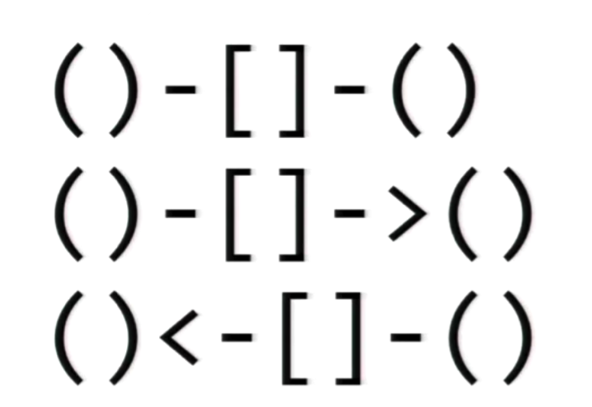
Język zapytań Cypher - zapisywanie i odczytywanie danych z Neo4j
Cypher to język zapytań grafowych baz danych Neo4j, który umożliwia pobieranie danych, aktualizację danych i administrację grafami. Został zaprojektowany tak, aby był odpowiedni zarówno dla programistów, jak i specjalistów operacyjnych. Cypher jest prosty, ale potężny; bardzo skomplikowane zapytania do bazy danych można łatwo wyrazić, co pozwala skupić się na właściwej pracy, zamiast tracić czas na pisanie skomplikowanego kodu. Cypher pierwotnie miał być używany z grafową bazą danych Neo4j, ale został otwarty w ramach projektu openCypher w październiku 2015 r.
Struktura języka Cypher
Cypher zapożycza swoją strukturę z SQL — zapytania są budowane przy użyciu różnych klauzul. Klauzule są ze sobą połączone i przekazują między sobą pośrednie zestawy wyników. Na przykład pasujące zmienne z jednej klauzuli MATCH będą kontekstem, w którym istnieje następna klauzula. Język zapytań składa się z kilku odrębnych klauzul.
Eksport danych z Neo4j
Jak pobrać dane z grafowej bazy danych Neo4j
W artykule "Ładowanie danych do Neo4j" opisane były metody ładowania danych do Neo4j. Teraz zajmiemy się tematyką pobierania danych z bazy. Możemy dokonać eksportu zawartości bazy na kilka sposobów w zależności jaki ma być format danych i czy dane będą pobierane automatycznie czy ręcznie.
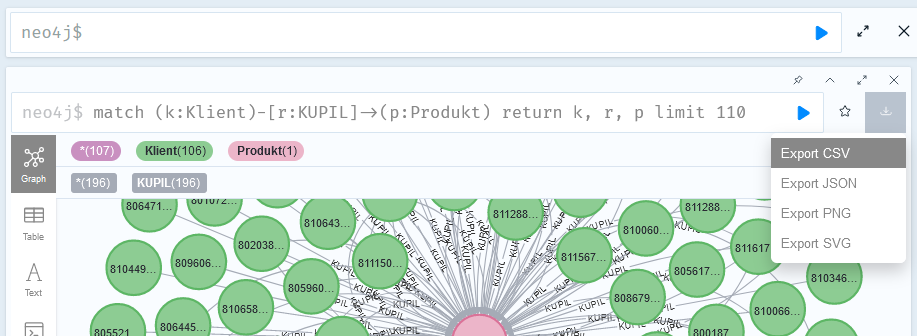
Pobieranie danych bezpośrednio z przeglądarki
Możesz dokonać eksportu danych bezpośrednio z okna przeglądarki (webowy interfejs do bazy Neo4j). Po wykonaniu zapytania Cypher kliknij ikonę eksportu po prawej stronie okna zapytań. Możesz wybrać jeden z kilku formatów. CSV czy JSON utworzy plik tekstowy który dalej możesz przetworzyć w innych narzędziach. PNG czy SVG będzie potrzebny kiedy bedziesz chciał(a) przedstawić dane np. w prezentacji.