Ticketing tool or BPM platform?
How to organize the environment of custom-built applications and ticket handling tools even more effectively and speed up processes.
Every company has a certain set of applications that are specially developed to support company needs or used in specific way to support some processes running within organization. Custom-built software or application is built specifically for what you need it for - the specific needs of your business.
To avoid communication chaos, we often use tools that are specialized in ticket handling. Ticketing system organizes activities and communication between the customer, the company, and the company teams in charge of meeting demands. In the vast majority of business applications we have some kind of workflow and process organization of work, but ticketing software provides a higher level of work organization, setting priorities, process follow-up and analyzing result.
Our dedicated applications are most often used to work with data and Help Desk/Service Desk systems are used to manage processes.
However, in such an organized architecture, we quickly notice gaps. In every business, a group of people do their job to "deliver value". But we don't do everything together and we break the task into activities because we specialize and carry out tasks according to skills - role. We do our job and pass it on to the next person - like an assembly line. If our production line consists of many unconnected sections, the process is not very effective. These are some of the challenges to deal with.
Information exchange (Interoperability) needed
In order to guarantee a productive, efficient and intelligent work that adds value, reduces costs and is scalable, interoperability is essential. It is impossible to carry out all company operations in one system and companies usually use many dedicated applications to perform various tasks. However, processes often pass through more than one system and therefore data exchange between them is required.
Lack of visibility is killing productivity
Resource shortages, communication frustration, and missed due dates - these can be an outcome of a lack of visibility. It’s pretty common to find teams or employees that are very good at their own tasks, but they have no global view of the company.
If we do not have a clear picture of the entire process, it is difficult to identify potential bottlenecks. Without centralized information about quality, execution time and resources used to perform individual tasks in the process - we are not able to measure or improve the process and therefore we do not manage it.
Applications are expensive
Software is the engine of today’s business - bloodstream of economy. But software cost a fortune. The global software market is predicted to reach a value of 872.72 billion of USD by 2028 [Skyquest Technology Consulting].
The ticketing software we are talking about here, which helps handle corporate processes, is becoming more and more sophisticated and its price is increasing every year - the bigger pool of users, the higher cost it is. Not all users use this class of software in the same intensive way - quite often we have a situation when simply reading information is not enough, but access to full functionality is excessive.
Multiple instance of the same category systems within the company
For various reasons, companies often have multiple instances of software that support processes; ticketing, project tasks and collaboration.
Sometimes it is the legacy of the organizations that have been brought together, sometimes it is conscious choices due to different needs or simply units location but the consequence is always same- these apps remain unconnected.
It can be done in a better way
In fact, most modern ticketing applications offer great freedom in creating configurations tailored to various needs and the ability to connect to various systems. But sooner or later we reach a wall where we have to sacrifice too much to get little, and some of the problems described above remain anyway.
Let's take as an example the onboarding of a new employee in a company. When a new person is hired, a number of activities is performed; employee is created in the systems, equipped with the equipment necessary and properly trained to start work. A sample process diagram might look like below.

Tworzenie osadzeń [embeddings] dla wyszukiwania wektorowego Neo4j
Jeśli temat 'wyszukiwania wektorowego' jest dla Ciebie nowy, przejdź na wcześniejszą stronę tego bloga by zapoznać się z tym przedmiotem. W tym artykule dowiesz się jak tworzyć osadzenia - wektory w wielowymiarowej przestrzeni. Czyli zamiana słów, zdań i zapytań na wektory.
Odczytanie danych z pliku Excela
Tworzymy embeddings dla opisów produktów. Nasza baza produktów znajduje się w pliku Excela. Użyjemy modułu pandas który wykorzystuje openpyxl by odczytać plik Excela. Utworzone wektory zapiszemy w pliku emb_result.csv [kolumny sku;description;embedding]
from sentence_transformers import SentenceTransformer
import numpy as np
import pandas as pd
import re
#Model 50 jezykow w tym Polski
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
#Sprawdzmy ile tokenów słów obsługuje model:
print("Max Sequence Length:", model.max_seq_length)
#Ustawienie maksymalnej długości kodowanych sekwencji
model.max_seq_length = 128
#Otwarcie pliku Excela, skoroszyt 0
file_name = "produkty.xlsx"
sheet = 0
#Otwarcie pliku, kolumny 0 i 19
df = pd.read_excel(io=file_name, sheet_name=sheet, usecols=[0, 19])
#Listuj 5 pierwszych linii pliku
#print(df.head(5))
#Testowy zapis do pliku:
#kolumna_do_zapisu = df[['sku', 'product description']]
#kolumna_do_zapisu.to_csv('test.csv', index=False)
file = open("emb_result.csv", "w", encoding='utf-8')
for index, row in df.iterrows():
emb = model.encode(row['product description'])
emb_str = np.array2string(emb, separator=',')
emb_str = emb_str.replace("\n","")
emb_str =emb_str.replace(" ","")
emb_str = re.sub(r'[\[\]]', '', emb_str)
file.write(str(row['sku']) + ';' + row['product description'] + ';' + emb_str)
file.write("\n")
file.close()
Wyszukiwanie wektorowe - algorytmy "Sztucznej Inteligencji"
Co to jest wyszukiwanie wektorowe?
Wektory to matematyczne reprezentacje danych w przestrzeni wielowymiarowej. W tej przestrzeni każde dane posiadają swoje koordynaty, a do reprezentowania skomplikowanych danych można użyć dziesiątek tysięcy wymiarów.. Słowa, frazy lub całe dokumenty, a także obrazy, pliki audio i inne typy danych można wektoryzować. Np. dla każdego opisu produktu obliczany jest wektor cech - tzw. "osadzenie" (po angielsku "embeddings"). Wyszukując informacji podobnych, używamy algorytmów które dostarczają nam informacje zapisane w podobnych lokalizacji przestrzeni wielowymiarowej co informacja referencyjna. Np. "pies" znajduje się niedaleko "pieska" czy "szczeniaka" (dla uproszczenia, bo jak napisaliśmy wyżej można umieścić tam całe dokumenty, obrazy, dźwięk).
Najpopularniejsze metody obliczania odległości miedzy informacjami umieszczonymi w przestrzenie (podobieństwo między wektorami) to metoda Euclidesa i Cosine. Sam Euclid żył 300 lat przed naszą erą więc dużo to mówi o haslach "nowoczesne algorytmy" i "sztuczna inteligencja".
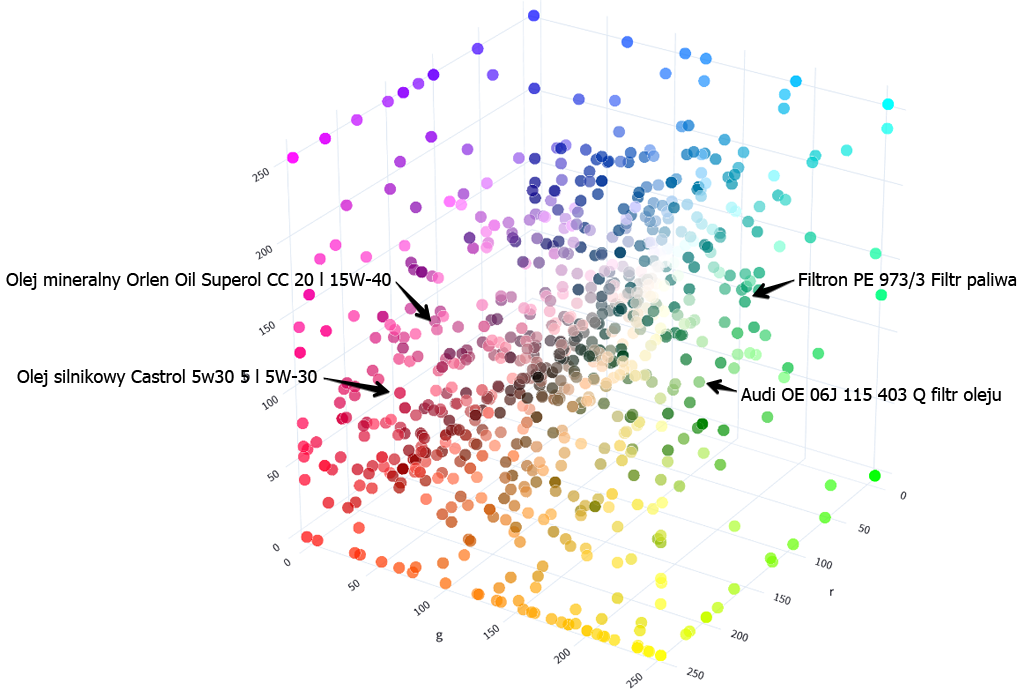
Wyobraź sobie że wszystkie produkty sklepu internetowego znalazły się w takiej wielowymiarowej przestrzeni a każdy z nich jest opisany wektorami; ma swoje miejsce w tej przestrzeni. Dla uproszczenia tak mogłoby wyglądać miejsce gdzie przechowujemy opis dwóch filtrów (prawa strona obrazka) i dwóch olejów silnikowych (lewa strona obrazka):
Personalizowane rekomendacje produktów
Rekomendacje produktów na podstawie danych z poprzednich transakcji zakupowych klientów
Według XYZ aż 91% konsumentów uważa, że chętniej kupią od marek, których rekomendacje i oferta są do nich dopasowane.... bla, bla bla. Rekomendacje, jeśli nie zbyt nachalne, z pewnością pomagają zwiększyć sprzedaż i uczynić klienta bardziej usatysfakcjonowanym. Kiedy mówimy o 'rekomendacjach' to mamy na myśli nie tylko sklepy internetowe ale e-mailing, oferty, podpowiedzi sprzedażowe w CRM itd. Poniżej kilka przykładów jak można je uzyskać w grafowej bazie danych Neo4j.
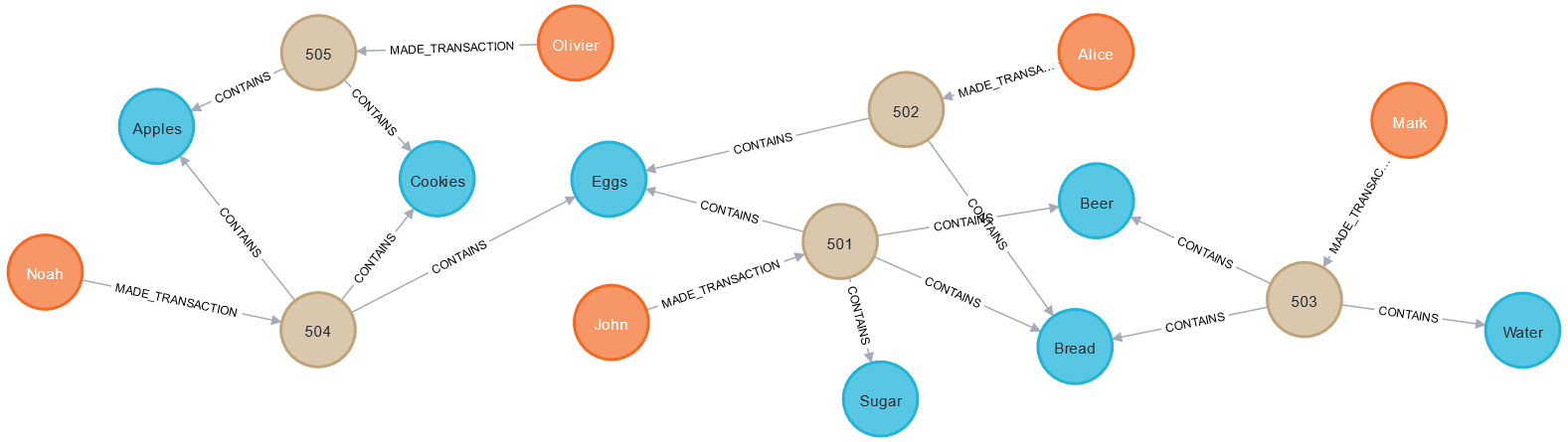
Przykładowe dane zakupowe
Nasze przykładowe dane to ledwie pięciu klientów kupujących sześć produktów. Gotowe do wgrania dane [użyj czystej bazy danych Neo4j]:
CREATE (John:Client {clientid: 10, name:'John'}),
(Alice:Client {clientid: 20, name:'Alice'}),
(Mark:Client {clientid: 30, name:'Mark'}),
(Noah:Client {clientid: 40, name:'Noah'}),
(Olivier:Client {clientid: 50, name:'Olivier'}),
(Eggs:Product {name:'Eggs', productid: 310}),
(Bread:Product {name:'Bread', productid: 320}),
(Beer:Product {name:'Beer', productid: 330}),
(Sugar:Product {name:'Sugar', productid: 340}),
(Cookies:Product {name:'Cookies', productid: 350}),
(Apples:Product {name:'Apples', productid: 360}),
(Water:Product {name:'Water', productid: 370}),
(t501:Transaction {id: 501, pdate: '2023-02-01'}),
(t502:Transaction {id: 502, pdate: '2023-02-02'}),
(t503:Transaction {id: 503, pdate: '2023-02-01'}),
(t504:Transaction {id: 504, pdate: '2023-02-04'}),
(t505:Transaction {id: 505, pdate: '2023-02-06'}),
(John)-[:MADE_TRANSACTION]->(t501),
(Alice)-[:MADE_TRANSACTION]->(t502),
(Mark)-[:MADE_TRANSACTION]->(t503),
(Noah)-[:MADE_TRANSACTION]->(t504),
(Olivier)-[:MADE_TRANSACTION]->(t505),
(t501)-[:CONTAINS {quantity: 2}]->(Eggs),
(t501)-[:CONTAINS {quantity: 3}]->(Bread),
(t501)-[:CONTAINS {quantity: 5}]->(Beer),
(t501)-[:CONTAINS {quantity: 4}]->(Sugar),
(t502)-[:CONTAINS {quantity: 3}]->(Eggs),
(t502)-[:CONTAINS {quantity: 4}]->(Bread),
(t503)-[:CONTAINS {quantity: 5}]->(Bread),
(t503)-[:CONTAINS {quantity: 6}]->(Beer),
(t503)-[:CONTAINS {quantity: 2}]->(Water),
(t504)-[:CONTAINS {quantity: 12}]->(Eggs),
(t504)-[:CONTAINS {quantity: 7}]->(Cookies),
(t504)-[:CONTAINS {quantity: 14}]->(Apples),
(t505)-[:CONTAINS {quantity: 32}]->(Apples),
(t505)-[:CONTAINS {quantity: 1}]->(Cookies);
Model danych
W naszych danych mamy trzy typy węzłów: Client, Product i Transaction. Zakupy klienta znajdują się w transakcjach których dokonał - między klientem a transakcją mamy relację MADE_TRANSACTION a produkty powiązane są z transakcją relacjami CONTAINS. Możesz wykonać polecenie call db.schema.visualization by zobaczyć ten model danych.

Widok grafu
Nasze dane po załadowaniu do Neo4j będą mieć następująca postać: