Ładowanie danych do Neo4j
Jak wgrać dane do grafowej bazy danych Neo4j
Z kursu wprowadzającego dowiedziałe(a)ś się jak rozpocząć przygodę z grafową bazą danych Neo4j. Zawarte były tam przykłady jak tworzyć węzły, ich właściwości oraz relacje między węzłami. W środowisku produkcyjnym nie będziesz jednak tworzyć węzłów ręcznie - najczęściej danych jest zbyt dużo. Poniżej znajdziesz kilka przykładów jak załadować do bazy duże ilości danych, dodać informację do już istniejącej i, co najważniejsze, jak zrobić to szybko.
Ładowanie danych z pliku CSV
Domyślnie Neo4j pozwala jedynie na wgranie danych z plików CSV które znajdują się w katalogu "import" instalacji Neo4j. Jeśli chcesz to zmienić, zakomentuj linię jak niżej w konfiguracji Neo4j - neo4j.conf
dbms.directories.import=import
Jeśli chcesz załadować plik do maksymalnie 10 milionów rekordów, użyj do tego polecenia LOAD CSV. Załóżmy że nasz przykładowy plik CSV ma postać (separatorami są tabulatory):
numer_klienta nazwisko adres
400230 Jan Pertek Opole
Jan Kowalski
400235 Monika Gered
400200 Grzegorz Stec Warszawa
Zanim zaczniesz wgrywć dane do bazy Neo4j musisz wiedzieć jedna ważną rzecz. Tak samo jak i w relacyjnej bazie danych, ogromny wpływ na szybkość działania bazy danych mają indeksy. Jeśli Twoja baza danych nie jest niewielką, testową bazą koniecznie utwórz indeksy.
CREATE INDEX numer_klienta FOR (k:Klient)
ON (k.numer_klienta)
Sprawdzić istniejące indeksy możesz wykonując polecenie:
CALL db.indexes
Jeśli chcesz skasować niepotrzebny indeks, zrób to poleceniem: DROP INDEX ON :Klient(numer_klienta). Jesteśmy teraz gotowi do załadowania danych z pliku. Polecenie Cypher które załaduje dane do bazy będzie mieć postać:
LOAD CSV WITH HEADERS FROM 'file:///test_data.csv' AS row FIELDTERMINATOR '\t'
WITH row WHERE row.numer_klienta IS NOT NULL
MERGE (k:Klient {numer_klienta: toInteger(row.numer_klienta), adres: coalesce(row.adres, "Nieznany")})
Pierwsza linijka to otwarcie pliku - informujemy Neo4j że separatorami w tym pliku są tabulatory. Druga linijka mówi że interesują nas tylko te linie gdzie numer_klienta nie jest pusty. Ostatnia linijka polecenia to utworzenie węzłów. MERGE albo dopasowuje istniejące węzły i wiąże je, albo tworzy nowe dane i wiąże je. To jak połączenie MATCH i CREATE, które dodatkowo pozwala określić, co się stanie, jeśli dane zostaną dopasowane lub utworzone. Funkcja "coalesce" wybiera pierwszą nie pustą wartość z listy (jeśli "row.adres" jest pusty, wybierze "Nieznany").
Możesz wykonać ćwiczenie i wykonać ten kod Cypher raz jeszcze, nie zmieniając testowych danych. Zobaczysz ze Neo4j nie utworzy tych samych węzłów raz jeszcze. Nowe węzły powstaną jeśli zmieni się któreś z pól w pliku (i wartość właściwości węzła).
Tworzenie węzłów i relacji między nimi w jednym czasie
Nie musisz wykonać kilku operacji by ładując dane z pliku utworzyć węzły i relacje między nimi. Wszystko to jesteś w stanie zrobić wykonując jeden kod. Załóżmy że masz w potrzebę połączenia zakupów klientów z produktami. Do tych informacji będziemy chcieli później dodać inne dane. Sprzedaż produktów mamy w pliku który ma format:
numer_klienta|numer_produktu|ilosc|cena|data_zakupu
100|200|2|56.90|2021-10-01
100|200|1|57|2021-10-02
100|210|4|12|2021-10-02
200|200|1|100.55|2021-10-01
200|300|1|88|2021-10-03
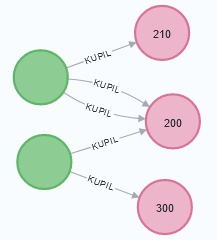
Po załadowaniu zawartości tego pliku będziemy mieć węzły "Klient", "Produkt" i relacje między nimi. By to uzyskac, wykonujemy kod:
LOAD CSV WITH HEADERS FROM 'file:///zakupy.csv' AS row FIELDTERMINATOR '|'
MERGE (c:Klient {numer_klienta: toInteger(row.numer_klienta)})
MERGE (p:Produkt {numer_produktu: toInteger(row.numer_produktu)})
WITH apoc.date.format(apoc.date.parse(row.data_zakupu, 'ms', 'yyyy-MM-dd'), 'ms', 'yyyy-MM-dd') as zakupdta, c, p, row
MERGE(c)-[:KUPIL {data_zakupu: zakupdta, cena: toFloat(row.cena)}]->(p)
Zaważ że użyliśmy tutaj biblioteki APOC by odpowiednio sformatować datę zakupu. Pamiętasz, że wszystkie dane które wczytujesz z CSV są typu string (tekst). Jeśli teraz sprawdzimy zawartość bazy danych poleceniem "MATCH (n) RETURN n" zobaczymy węzły i relacje między nimi:
Dodawanie właściwości do węzłów
Następnym etapem będzie dodanie do węzłów "Produkt" dodatkowych właściwości. Podczas tworzenia tych węzłów dodaliśmy do produktu właściwość "numer_produktu". Chcielibyśmy dodać też inne informacje: opis produktu i nazwę dostawcy produktu. Informacje te mamy w następnym pliku:
numer_produktu|opis_produktu|nazwa_dostawcy
200|Szorty czerwone|Unitex
210|Kamizelka|Peleo
300|T-shirt|Force Game
Wykonajmy poniższy kod by dodać te właściwości do węzłów "Produkt":
LOAD CSV WITH HEADERS FROM 'file:///produkty.csv' AS row FIELDTERMINATOR '|'
MATCH (p:Produkt {numer_produktu: toInteger(row.numer_produktu)})
SET p.opis_produktu = row.opis_produktu, p.nazwa_dostawcy = row.nazwa_dostawcy
Jeśli ponownie odświeżysz zawartość bazy, zobaczysz że nowe właściwości zostały dodane do produtków.
Dodajemy nowe węzły i tworzymy relacje z nimi
Nastepnym ćwiczeniem będzie dodanie kolejnych węzłów i zbudowanie relacji między już istniejącymi a tymi nowymi. Wyobraźmy sobie że mamy plik w którym zawarta jest informacja jakie strony polubił klient. Np. otrzymałe(a)ś w firmie takie informacje od e-commerce by je połączyć z informacją o kliencie i jego zakupach. Struktura tego pliku mogłaby wyglądać tak:
numer_klienta|numer_strony|opis_strony
100|900|Blog - zastosowanie produktu X
100|901|Blog - prezentacja produktu X
200|900|Blog - prezentacja produktu Z
200|901|Blog - prezentacja produktu Y
200|700|Blog - warunki zakupów
Dołączmy te informacje do istniejących danych:
LOAD CSV WITH HEADERS FROM 'file:///polubienia.csv' AS row FIELDTERMINATOR '|'
MATCH
(k:Klient {numer_klienta: toInteger(row.numer_klienta)})
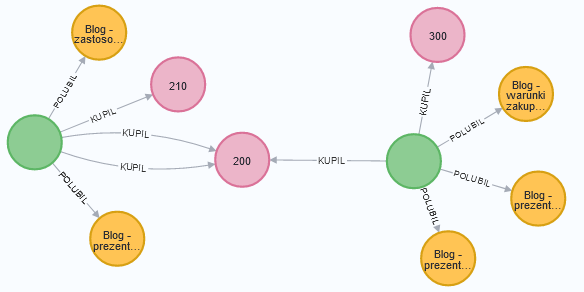
MERGE (s:Strona {numer_strony: toInteger(row.numer_strony), opis_strony: row.opis_strony})
MERGE (k)-[r:POLUBIL]->(s)
Jeśli teraz sprawdzisz jak wygląda graf z danymi, jego postać będzie następująca:
Jak jeszcze inaczej wgrać dane do Neo4j lub je uzupełnić?
APOC i odpowiedni sterownik bazy danych
Zobacz artykuł na ten temat. Opisaliśmy tam jak uzyskać z poziomu Neo4j połączenie z relacyjną bazą danych.
ETL Kettle
Kettle (Penthato PDI) to elastyczne narzędzie do ładowania danych które ma kilka opcji połączeń z Neo4j, a także możliwości generowania plików CSV z innych systemów w celu załadowania ich do grafowej bazy danych. W tym oprogramowaniu możesz w prosty sposób stworzyć łatwy w utrzymaniu procesu integracji danych i zarządzania nim od początku do końca. Kettle buduje proces ładowania danych, który jest przejrzysty. Jest to szczególnie przydatne, gdy import danych wymaga pobrania danych z wielu źródeł lub jeśli istnieje wiele zależnych kroków do zbudowania lub zaktualizowania grafu. Jeśli potrzebujesz przekształcić dane przychodzące lub wychodzące, Kettle może obsługiwać różne rodzaje transformacji, w tym agregacje. Cała ta funkcjonalność jest dostępna w prostym, ale potężnym graficznym interfejsie użytkownika. By Kettle mógł współpracować z Neo4j - niezbędna jest instalacja odpowiedniej wtyczki.
Pobieranie danych z Neo4j
W następnym artykule opisaliśmy jak pobrać dane z Neo4j.