Personalizowane rekomendacje produktów
Rekomendacje produktów na podstawie danych z poprzednich transakcji zakupowych klientów
Według XYZ aż 91% konsumentów uważa, że chętniej kupią od marek, których rekomendacje i oferta są do nich dopasowane.... bla, bla bla. Rekomendacje, jeśli nie zbyt nachalne, z pewnością pomagają zwiększyć sprzedaż i uczynić klienta bardziej usatysfakcjonowanym. Kiedy mówimy o 'rekomendacjach' to mamy na myśli nie tylko sklepy internetowe ale e-mailing, oferty, podpowiedzi sprzedażowe w CRM itd. Poniżej kilka przykładów jak można je uzyskać w grafowej bazie danych Neo4j.
Przykładowe dane zakupowe
Nasze przykładowe dane to ledwie pięciu klientów kupujących sześć produktów. Gotowe do wgrania dane [użyj czystej bazy danych Neo4j]:
CREATE (John:Client {clientid: 10, name:'John'}),
(Alice:Client {clientid: 20, name:'Alice'}),
(Mark:Client {clientid: 30, name:'Mark'}),
(Noah:Client {clientid: 40, name:'Noah'}),
(Olivier:Client {clientid: 50, name:'Olivier'}),
(Eggs:Product {name:'Eggs', productid: 310}),
(Bread:Product {name:'Bread', productid: 320}),
(Beer:Product {name:'Beer', productid: 330}),
(Sugar:Product {name:'Sugar', productid: 340}),
(Cookies:Product {name:'Cookies', productid: 350}),
(Apples:Product {name:'Apples', productid: 360}),
(Water:Product {name:'Water', productid: 370}),
(t501:Transaction {id: 501, pdate: '2023-02-01'}),
(t502:Transaction {id: 502, pdate: '2023-02-02'}),
(t503:Transaction {id: 503, pdate: '2023-02-01'}),
(t504:Transaction {id: 504, pdate: '2023-02-04'}),
(t505:Transaction {id: 505, pdate: '2023-02-06'}),
(John)-[:MADE_TRANSACTION]->(t501),
(Alice)-[:MADE_TRANSACTION]->(t502),
(Mark)-[:MADE_TRANSACTION]->(t503),
(Noah)-[:MADE_TRANSACTION]->(t504),
(Olivier)-[:MADE_TRANSACTION]->(t505),
(t501)-[:CONTAINS {quantity: 2}]->(Eggs),
(t501)-[:CONTAINS {quantity: 3}]->(Bread),
(t501)-[:CONTAINS {quantity: 5}]->(Beer),
(t501)-[:CONTAINS {quantity: 4}]->(Sugar),
(t502)-[:CONTAINS {quantity: 3}]->(Eggs),
(t502)-[:CONTAINS {quantity: 4}]->(Bread),
(t503)-[:CONTAINS {quantity: 5}]->(Bread),
(t503)-[:CONTAINS {quantity: 6}]->(Beer),
(t503)-[:CONTAINS {quantity: 2}]->(Water),
(t504)-[:CONTAINS {quantity: 12}]->(Eggs),
(t504)-[:CONTAINS {quantity: 7}]->(Cookies),
(t504)-[:CONTAINS {quantity: 14}]->(Apples),
(t505)-[:CONTAINS {quantity: 32}]->(Apples),
(t505)-[:CONTAINS {quantity: 1}]->(Cookies);
Model danych
W naszych danych mamy trzy typy węzłów: Client, Product i Transaction. Zakupy klienta znajdują się w transakcjach których dokonał - między klientem a transakcją mamy relację MADE_TRANSACTION a produkty powiązane są z transakcją relacjami CONTAINS. Możesz wykonać polecenie call db.schema.visualization by zobaczyć ten model danych.

Widok grafu
Nasze dane po załadowaniu do Neo4j będą mieć następująca postać:
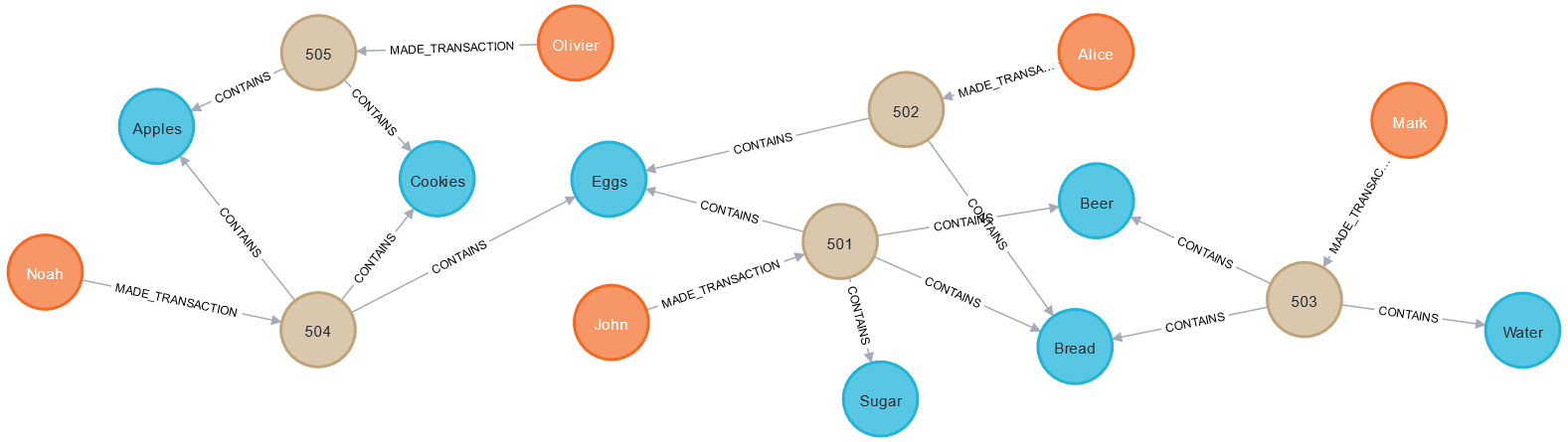
Jakie przedmioty są często kupowane razem?
Jeśli posiadamy taką wiedzę, możemy zaoferować powiązane produkty klientom którzy ich nie kupili. To wiedza która możemy też wykorzystać w różnego rodzaju kampaniach handlowych czy akcjach marketingowych - jeśli naszym celem jest sprzedaż produktu X, powinniśmy go zaoferować klientom którzy kupili produkt Y sprzedawany często właśnie z X. Poniższe zapytanie udostępni nam takie dane:
MATCH path = (product:Product)-[:CONTAINS]-(:Transaction)-[:CONTAINS]-(product2:Product)
WHERE id(product) > id(product2)
WITH product, product2, count(distinct path) as Instances
ORDER BY Instances DESC
LIMIT 8
RETURN product.name AS product1, product2.name AS product2, Instances;

Co jeszcze innego kupili klienci z podobnymi zakupami?
W personalizowanym marketingu chcielibyśmy poznać co jeszcze możemy zaoferować klientowi o imieniu John (id klienta: 10). Wyświetlmy co jeszcze kupili klienci którzy mają co najmniej dwa wspólne produkty w transakcjach zakupowych:
MATCH (c:Client {clientid: 10})-[:MADE_TRANSACTION]-(:Transaction)-[:CONTAINS]->(p:Product)<-[:CONTAINS]-(:Transaction)-[:MADE_TRANSACTION]-(c2:Client)
WITH c2, collect(p) as productsInCommon
WHERE size(productsInCommon) >= 2
OPTIONAL MATCH (c2)-[:MADE_TRANSACTION]-(:Transaction)-[:CONTAINS]->(p2:Product)
WHERE NOT p2 IN productsInCommon AND p2 is not null
RETURN DISTINCT p2.productid, p2.name ORDER BY p2.name
Jak widzimy klienci którzy mieli w transakcja co najmniej dwa takie produkty które kupił John kupili jeszcze wodę (wodę kupił Mark)

Szukamy podobnych klientów
Podobny klient lub podobni klienci (alike lub lookalike) do klienta X może/mogą podpowiedzieć nam co jeszcze mógłby nasz X kupić. Ci podobni klienci mają podobną historię zakupów lub innych cech (także biorąc wszystkie je pod uwagę) - wiek, branża, płeć, ilość pracowników...
Znalezienie podobnych klientów rozpoczynamy od stworzenia grafu w pamięci bazy danych. Czym są te grafy i jak się je tworzy zobacz w tym artykule.
Projekcje z użyciem języka Cypher są bardziej elastycznym i wyrazistym podejściem w porównaniu do projekcji natywnych przy tworzeniu grafów. Oto polecenie utworzenia grafu:
MATCH (source:Client)-[:MADE_TRANSACTION]-(:Transaction)-[:CONTAINS]->(target:Product)
WITH gds.graph.project('purchases', source, target) AS g
RETURN
g.graphName AS graph, g.nodeCount AS nodes, g.relationshipCount AS rels
W efekcie otrzymamy rezultat wykonania tego polecenia - utworzony został graf 'purchases' zawierający 12 węzłów z 14 relacjami między nimi:

Inny sposób utworzenia takiego grafu:
CALL gds.graph.project.cypher(
'purchases',
'MATCH (n) WHERE n:Client OR n:Product RETURN id(n) AS id',
'MATCH (c:Client)-[:MADE_TRANSACTION]-(:Transaction)-[:CONTAINS]->(p:Product) RETURN id(c) AS source, id(p) as target'
)
Mając graf, możemy teraz użyć algorytmu nodeSimilarity by znaleć podobnych klientów. Parametr degreeCutoff określa minimalną liczbę krawędzi (relacji), które algorytm bierze pod uwagę podczas obliczeń podobieństwa. Jeśli ustawisz degreeCutoff na określoną wartość, to algorytm uwzględni jedynie wierzchołki (węzły),
które są połączone z danym wierzchołkiem przez nie mniej niż tę liczbę krawędzi - minimalna liczba relacji po drodze.
Parametr similarityCutoff określa dolną granicę stopnia podobieństwa porównywanych węzłów.
CALL gds.nodeSimilarity.stream('purchases',
{
degreeCutoff: 2, similarityCutoff: 0.5
}
)
YIELD node1, node2, similarity
RETURN
gds.util.asNode(node1).name AS Client1,
gds.util.asNode(node2).name AS Client2,
ROUND(similarity, 2) as similarity
ORDER BY similarity DESCENDING, Client1, Client2
Rezultat wykonania tego algorytmu:

Sprawdzmy teraz jedną z par podobnych klientów, jakie wspólne zakupy łączą 'John' i 'Alice':
MATCH (c:Client)-[:MADE_TRANSACTION]-(t:Transaction)-[:CONTAINS]->(p:Product)
WHERE c.name = 'Alice' OR c.name ='John'
RETURN c, t, p
Rezultat wykonania zapytania:

Wspólne produkty który kupili to 'Bread' i 'Eggs' co spowodowało że przy tak krótkiej liście ich zakupów otrzymali wskaźnik dopasowania 0,5. Gdybyśmy używali prawdziwych danych klientów, klienci mieliby atrybuty takie jak wiek, płeć, adres zamieszkania, wartość dokonanych zakupów... wymień inne. Dałoby to nam większe dopasowanie klientów ponieważ algorytm wziąłby pod uwagę nie tylko listę zakupionych artykułów przez porównywanych klientów.
Jakie artykuły są najczęściej spotykane?
Powyżej wyszukaliśmy podobnych klientów i ich zakupy. A co jeśli byśmy chcieli zobaczyć jakie artykuły są najczęściej spotykane w tych samych zakupach? Jak wygląda 'podobieństwo' artykułów - klient który kupuje X, prawdopodobnie kupuje również Y.
Odwróćmy zatem kierunek naszych relacji w grafie i wyjdźmy nie od klienta do artykułu ale w drugim kierunku:
MATCH (source:Product)-[:CONTAINS]-(:Transaction)-[:MADE_TRANSACTION]-(target:Client)
WITH gds.graph.project('article-purchases', source, target) AS g
RETURN g.graphName AS graph, g.nodeCount AS nodes, g.relationshipCount AS rels
A następnie użyjmy algorytmu nodeSimilarity by wyświetlić artykuły które często powinny być sprzedawane razem:
CALL gds.nodeSimilarity.stream('article-purchases',
{
degreeCutoff: 2,
similarityCutoff: 0.5
}
)
YIELD node1, node2, similarity
RETURN
gds.util.asNode(node1).name AS Product1,
gds.util.asNode(node2).name AS Product2,
ROUND(similarity, 2) as similarity
ORDER BY similarity DESCENDING, Product1, Product2
Oto co otrzymamy jako rezultat użycia tego algorytmu:

Zobaczmy co jeszcze innego kupili klienci którzy kupili 'Beer':
MATCH (p1:Product {name: "Beer"})<--(t:Transaction)-->(p2:Product)
RETURN p1.name, p2.name
Rezultat tego zapytania:

Być może zainteresuje Cię także w jaki sposób możesz zbudować klastry klientów - instrukcje znajdziesz w artykule 'Rekomendacje bazujące na poprzednich zakupach klientów'. Jeśli chcesz dowiedzieć się więcej jak zbudować system rekomendacji, przeczytaj ten artykuł.