Bibioteka Graph Data Science w bazie Neo4j - algorytmy Node Similarity & Louvain
Rekomendacje bazujące na poprzednich zakupach klientów
Algorytm podobieństwa węzłów porównuje zbiór węzłów na podstawie węzłów, z którymi są one połączone. Dwa węzły są uważane za podobne, jeśli mają wielu takich samych sąsiadów. Funkcja podobieństwa węzłów oblicza podobieństwa parami na podstawie metryki Jaccarda, znanej również jako wynik podobieństwa Jaccarda, lub współczynnika nakładania się, znanego również jako współczynnik Szymkiewicza-Simpsona.
Metoda Louvaina to algorytm służący do wykrywania społeczności w dużych sieciach. Maksymalizuje wynik modułowości dla każdej społeczności, gdzie modułowość określa ilościowo jakość przypisania węzłów do społeczności. Oznacza to ocenę, o ile gęściej połączone są węzły w obrębie społeczności, w porównaniu z tym, jak połączone byłyby w losowej sieci.
Algorytm Louvaina jest algorytmem hierarchicznego grupowania, który rekurencyjnie łączy społeczności w jeden węzeł i wykonuje grupowanie modułowości na skondensowanych grafach. Algorytm Louvaina jest niedeterministyczny i dlatego niektóre węzły czasami są grupowane w społeczności, a czasami nie. To oznacza że rezultaty mogą być różne w różnych uruchomieniach programu.
Algorytm został opracowany na beligijskim Universytecie Louvain niedaleko Brukseli.
Uruchomienie biblioteki GDS
Bibliotekę dla Neo4j Server można pobrać ze strony https://neo4j.com/deployment-center/#gds-tab
Po rozpakowaniu pliku *.zip kopiujemy JAR do katalogu 'plugins' i modyfikujemy plik konfiguracyjny Neo4j ($NEO4J_HOME/conf/neo4j.conf) wstawiając w nim linie:
dbms.security.procedures.unrestricted=gds.*
Następnie pozwalamy na wykonywanie procedur z użyciem tej biblioteki wstawiająć kolejną linie w tym samym pliku konfiguracyjnym:
dbms.security.procedures.allowlist=gds.*
Po wgraniu pliku uruchom serwer ponownie by załadowac bliblioteką.
Sprawdzanie wersji oraz listy dostępnych algorytmów
Jeśli chcesz sprawdzić wersję biblioteki GDS uruchom polecenie:
RETURN gds.version();Listę dostępnych procedur i algorytmów sprawdzisz uruchamiając polecenie:
CALL gds.list();Budowa procesu rekomendacji produktów
Naszym celem jest zbudowanie procesu/silnika rekomendacji produktów bazującego na poprzednich zakupach klientów. Docelowo chcemy wykryć klastry klientów [przeczytaj niżej czym różni się klastrowanie od segmentacji] których wspólną cechą są podobne zakupy; zakupili pewną ilość takich samych produktów (choć także kupili i inne artykuły). Mając klastry klientów, możemy sporządzić listę najczęściej artykułów przez tych klientów. A skoro wiemy co inni podobni klienci kupują i czego nie kupił nasz klient, możemy mu taki produkt/produkty zaproponować.
Krokiem pośrednim będzie znalezienie podobieństw między klientami; określenie który klient jest podobny do którego pod kątem dokonanych zakupów. Sama informacja o podobieństwie może być także użyta w procesie rekomendacji; wiemy co kupili podobni klienci ale także możemy poznać które produkty są w ich zakupach wykazują takie podobieństwo. Klient który kupił produkt X może być także zainteresowany produktem Y ponieważ były one kupowane często wspólnie. Co więcej, znając zakupiony artykuł, możemy dowiedzieć się co jeszcze najczęściej kupowane jest przy zakupie tego właśnie produktu.
Przeczytaj też artykuł "Jak zbudować wydajny system rekomendacji produktów" na naszym blogu w którym objaśniamy jak z pomocą Neo4j stworzymć system rekomendacji produktów bazujący na zakupach osób które dokonały podobnych wyborów jak klient któremu będziemy rekomendować produkty (collaborative filtering). System z dużą skutecznością podpowie produkty, którymi naprawdę może być zainteresowany nasz klient.
Klastrowanie vs segmentacja
Klastrowanie wykorzystuje algorytmy do identyfikowania podobieństw w danych klientów. Mówiąc najprościej, algorytmy przeglądają dane klientów, wychwytują podobieństwa, które ludzie mogli przeoczyć, i grupują klientów w oparciu o wzorce ich zachowań.
Kiedy marketer wybiera kryteria, aby wyciągnąć określone grupy z dużego zbioru danych, jest to segmentacja. Innymi słowy, ma to miejsce wtedy, gdy patrzysz na dane swoich klientów i wybierasz konkretne kryteria, do których chcesz dotrzeć do danej grupy.
To tutaj ludzie używają głowy i, co dziwne, serca opartego na danych, aby dotrzeć do określonych grup i drążyć temat tak szczegółowo, jak chcą. Tam, gdzie klastry dostarczają informacji, segmentacja pozwala "marketerowi" wybierać i celowo kierować określone grupy w celu spersonalizowanego przekazu.
Przygotowanie danych - Grafy
Nie możesz uruchamiać algorytmów biblioteki GDS bezpośrednio na danych bazy Neo4j. Musisz użyć struktury pośredniej - grafu. Graf w bibliotece GDS to struktura znajdująca się w pamięci zawierająca węzły połączone relacjami. Zarówno węzły, jak i relacje mogą przechowywać atrybuty numeryczne (właściwości). Wykresy są przechowywane przy użyciu skompresowanych struktur danych zoptymalizowanych pod kątem operacji wyszukiwania topologii i właściwości.
Każdy graf ma nazwę, która może służyć jako odniesienie w operacjach zarządzania lub w przepływach pracy analitycznych, które wymagają kilkukrotnego przetworzenia tego samego wykresu. Odniesienia te są przechowywane w katalogu grafów.
Utworzone grafy możesz odczytywać, modyfikować, zapisywać właściwości do istniejących danych, eksportować [do NOWYCH baz danych - miej w pamięci ograniczenia darmowej edycji Neo4j] lub plików CSV. Grafy ulegają skasowaniu w momencie zatrzymania/restartu bazy Neo4j [chyba że zrobisz ich backup].
Pamiętaj, że biblioteka Neo4j Graph Data Science nie obsługuje wszystkich typów właściwości obsługiwanych przez bazę danych Neo4j. Każdy obsługiwany typ definiuje również wartość rezerwową, która służy do wskazania, że wartość tej właściwości nie jest ustawiona.
W poniższej tabeli wymieniono obsługiwane typy właściwości, a także odpowiadające im wartości rezerwowe.
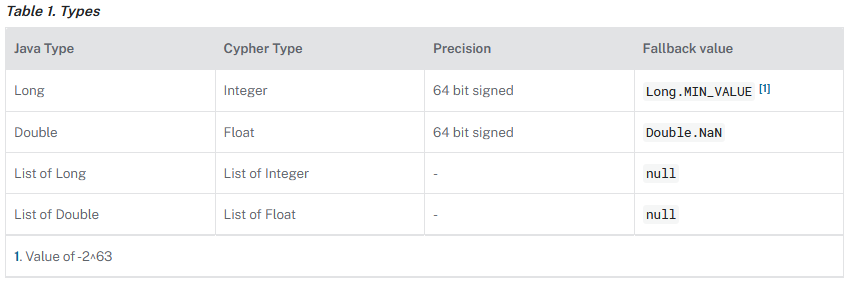
Więcej informacji na temat tworzenia grafów znajdziesz na stronie Neo4j.
Przygotowanie testowych danych
Nasze testowe dane to zakupy pięciu produktów przez czterech klientów. Niektórzy klienci kupili wielokrotnie te same produkty w różnym okresie czasu. Wizualizacja tych węzłów i relacji daje nam obraz:
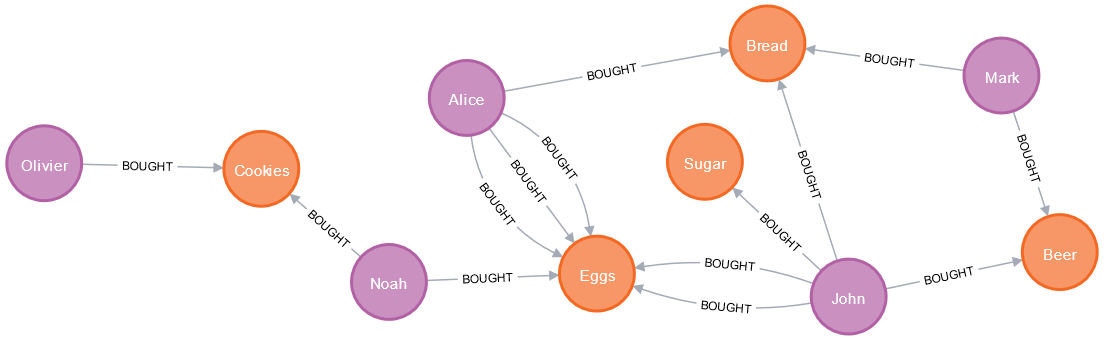
Oto gotowe dane które możesz użyć do testu (wgraj do czystej bazy):
CREATE (nJohn:Client {clientid: 10, name:'John'}),
(nAlice:Client {clientid: 20, name:'Alice'}),
(nMark:Client {clientid: 30, name:'Mark'}),
(nNoah:Client {clientid: 40, name:'Noah'}),
(nOlivier:Client {clientid: 50, name:'Olivier'}),
(nEggs:Product {name:'Eggs', productid: 310}),
(nBread:Product {name:'Bread', productid: 320}),
(nBeer:Product {name:'Beer', productid: 330}),
(nSugar:Product {name:'Sugar', productid: 340}),
(nCookies:Product {name:'Cookies', productid: 350}),
(nJohn)-[:BOUGHT {quantity: 2, purchased: '2023-01-01' }]->(nEggs),
(nJohn)-[:BOUGHT {quantity: 3, purchased: '2023-01-03' }]->(nEggs),
(nJohn)-[:BOUGHT {quantity: 3, purchased: '2023-01-02' }]->(nBread),
(nJohn)-[:BOUGHT {quantity: 5, purchased: '2023-01-01' }]->(nBeer),
(nJohn)-[:BOUGHT {quantity: 4, purchased: '2023-01-02' }]->(nSugar),
(nAlice)-[:BOUGHT {quantity: 3, purchased: '2023-01-06' }]->(nEggs),
(nAlice)-[:BOUGHT {quantity: 1, purchased: '2023-01-07' }]->(nEggs),
(nAlice)-[:BOUGHT {quantity: 1, purchased: '2023-01-09' }]->(nEggs),
(nAlice)-[:BOUGHT {quantity: 8, purchased: '2023-01-04' }]->(nBread),
(nMark)-[:BOUGHT {quantity: 3, purchased: '2023-01-01' }]->(nBread),
(nMark)-[:BOUGHT {quantity: 2, purchased: '2023-01-02' }]->(nBeer),
(nNoah)-[:BOUGHT {quantity: 6, purchased: '2023-01-02' }]->(nEggs),
(nNoah)-[:BOUGHT {quantity: 3, purchased: '2023-01-09' }]->(nCookies),
(nOlivier)-[:BOUGHT {quantity: 1, purchased: '2023-01-11' }]->(nCookies);
Tworzenie grafu w pamięci
Wiemy, że nie możemy uruchamiać algorytmów biblioteki GDS bezpośrednio na danych bazy Neo4j. Musimy użyć struktury pośredniej - grafu. Do naszego grafu załadujemy także właściwości 'clientid' (Client) i 'productid' (Product) - posłużą nam do tego by pokazać jak można odczytać graf. Tworzymy graf:
CALL gds.graph.project(
'purchases',
{
Client:{properties:'clientid'},
Product:{properties:'productid'}
},
{BOUGHT: {}}
)
Nazwa tego grafu to 'purchases'. Pierwszy zestaw zmiennych to typy węzłów; Client i Product. Ostatnia linijka to typ relacji. Na potrzeby innych analiz moglibyśmy także określić właściwości relacji, właściwości węzłów oraz kierunek relacji. Oto przykłady jak użyć takich opcji:
//Przykład 1:
CALL gds.graph.project(
'purchases',
['Client', 'Product'],
['BOUGHT'],
{nodeProperties: 'productid'}
)
//Przykład 2:
CALL gds.graph.project(
'purchases',
{
Client:{},
Product:{properties:'productid'}
},
{BOUGHT: {orientation: 'UNDIRECTED'}}
)
//Przykład 3:
CALL gds.graph.project(
'purchases',
['Client', 'Product'],
['BOUGHT']
)
Wykonanie algorytmów
Algorytm Node Similarity
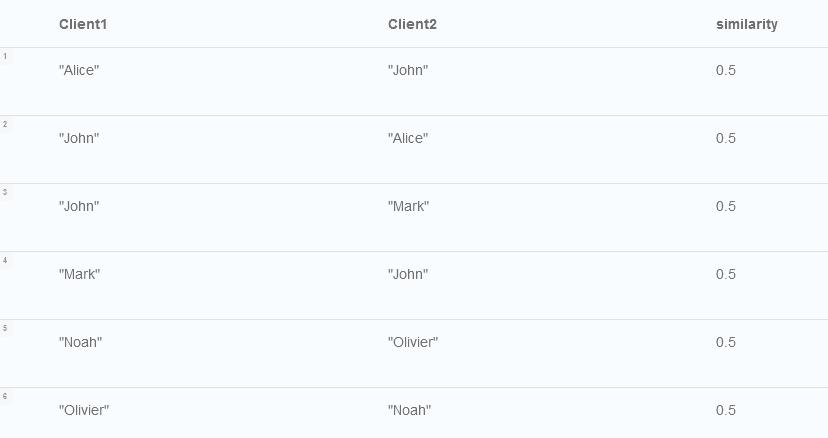
Wykonajmy teraz algorytm Node Similarity ktory obliczy podobieństwo klientów. Parametr 'similarityCutoff' to dolna granica obecności wyniku podobieństwa w wyniku. Wartości tego paramteru muszą należeć do zakresu od 0 do 1. Chcemy pominąć w wynikach wszystkich klientów których dopasowanie wynosi poniżej 0.3
CALL gds.nodeSimilarity.stream('purchases', {similarityCutoff: 0.3})
YIELD node1, node2, similarity
RETURN
gds.util.asNode(node1).name AS Client1,
gds.util.asNode(node2).name AS Client2,
similarity
ORDER BY similarity DESCENDING, Client1, Client2
CALL gds.nodeSimilarity.mutate(
'purchases', {mutateRelationshipType:'SIMILAR', mutateProperty:'score',topK:10, similarityCutoff:0.30}
)
Algorytm Louvain
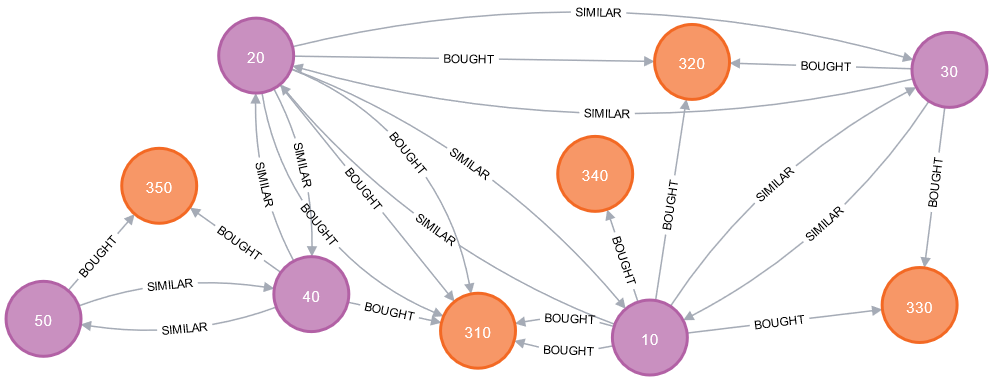
CALL gds.nodeSimilarity.write('purchases', {
writeRelationshipType: 'SIMILAR',
writeProperty: 'score'
})
YIELD nodesCompared, relationshipsWritten
CALL gds.louvain.stream('purchases',{nodeLabels: ['Client'], relationshipTypes:['SIMILAR'], relationshipWeightProperty:'score'})
YIELD nodeId, communityId
RETURN communityId, count(nodeId) as size
ORDER by size DESC

CALL gds.louvain.mutate('purchases', { mutateProperty: 'communityId' })
YIELD communityCount, modularity, modularities
Możemy też przypisać numer klastra do danych w samej bazie danych [funkcja 'write' algorytmu Louvain]:
CALL gds.louvain.write('purchases', { writeProperty: 'community' })
YIELD communityCount, modularity, modularities
Odczyt grafu
Poniżej znajdziesz dodatkowe informacje jak odczytywać informacje z grafu który znajduje się w pamięci.
Odczyt wartości właściwości w węzłach
Aby sprawdzić wartości właściwości w węzłach grafów GDS, można zastosować procedurę gds.graph.nodeProperties.stream. Jest to przydatne, jeśli uruchomiliśmy wiele algorytmów w trybie mutacji i chcemy odzyskać część lub wszystkie wyniki.
CALL gds.graph.nodeProperty.stream('purchases', 'clientid', ['*'])
YIELD nodeId, propertyValue
RETURN gds.util.asNode(nodeId).name AS name, propertyValue AS clientid
ORDER BY clientid DESC
Odczyt relacji
Aby sprawdzić tylko topologię relacji, można zastosować procedurę gds.graph.relationships.stream. Aby sprawdzić przechowywane wartości właściwości relacji, można zastosować procedurę relationsProperties.stream. Jest to przydatne, jeśli uruchomiliśmy wiele algorytmów w trybie mutacji i chcemy odzyskać część lub wszystkie wyniki.
CALL gds.graph.relationships.stream(
'purchases'
)
YIELD
sourceNodeId, targetNodeId, relationshipType
RETURN
gds.util.asNode(sourceNodeId).name as source, gds.util.asNode(targetNodeId).name as target, relationshipType
ORDER BY source ASC, target ASC
Kasowanie grafu
Graf ulega samoistnemu skasowaniu w momencie restartu bazy. By skasować go wcześniej [np. potrzeba utworzenia nowego] wykonaj następujące polecenie:
CALL gds.graph.drop('purchases')