
Zastosowanie algorytmu asocjacji w uczeniu maszynowym
Asocjacja to metoda uczenia maszynowego oparta na regułach służąca do wykrywania interesujących relacji między zmiennymi w bazach danych.
Ma na celu zidentyfikowanie wyraźnich reguł w zbiorach danych. Algorytm apriori jest najczęściej używany w biznesie by znaleźć odpowiedź które produkty sa sprzedawane razem.
Spojrzenie na przedmioty często kupowane razem, może dać sprzedawcom wyobrażenie o zachowaniach zakupowych klientów. Wiedza ta, uzyskana z danych, może być wykorzystana do ustalania cen, promocji marketingowych, zarządzania zapasami i tak dalej.
Algorytm apriori ma swoje zalety ale ma też jedną wadę - jego zastosowanie na dużym zbiorze danych może być problematyczne z uwagi na powolność działania. Być może zainteresuje Cie także inny algorytm FP-Growth który działa znacznie szybciej lub użycie grafowej bazy danych Neo4j by osiągnąć podobne cele.
Szukamy relacji w programie Weka - wczytujemy dane
„Jaki koszyk produktów występuje najczęściej?”
Możemy zadać też podobne pytanie, np: „Jakie produkty kupowane są najczęściej z hamburgerami?” Chcemy poznać korelacje, które zachodzą w zakupach klientów – poznać ich wzorce zakupowe. Załóżmy, że dysponujemy listą transakcji klientów:

Pola w kolumach "t" to oznaczenie, że w transakcji klienta nastąpił zakup tego artykułu. Puste cele oznaczają brak zakupu. By poznać reguły w zakupach użyjemy programu Weka. Weka do stworzenia reguł asocjacji wykorzystuje algorytm "apriori".
Uruchamiamy program Weka a następnie wybieramy "Explorer" w głownym oknie. W "Weka explorer" które otworzy nam się jako następne okno wybieramy plik z danymi. Dane mogą być w formacie CSV.
nr_transakcji;cebula;ziemniaki;hamburgery;mleko;piwo
t1;t;t;t;;
t2;;t;t;t;
t3;;;;t;t
t4;t;t;;t;
t5;t;t;t;;t
t6;t;t;t;;t
Po otwarciu pliku przechodzimy do zakładki "Associate". Tam domyślnie w oknie "Associator" mamy wpisany algorytm apriori. Jego ustawienia możemy zmienić klikajać na jego nazwę. Zostawmy to w tej chwili. Klikamy na "OK". Rezultat obliczeń pojawia się w oknie.
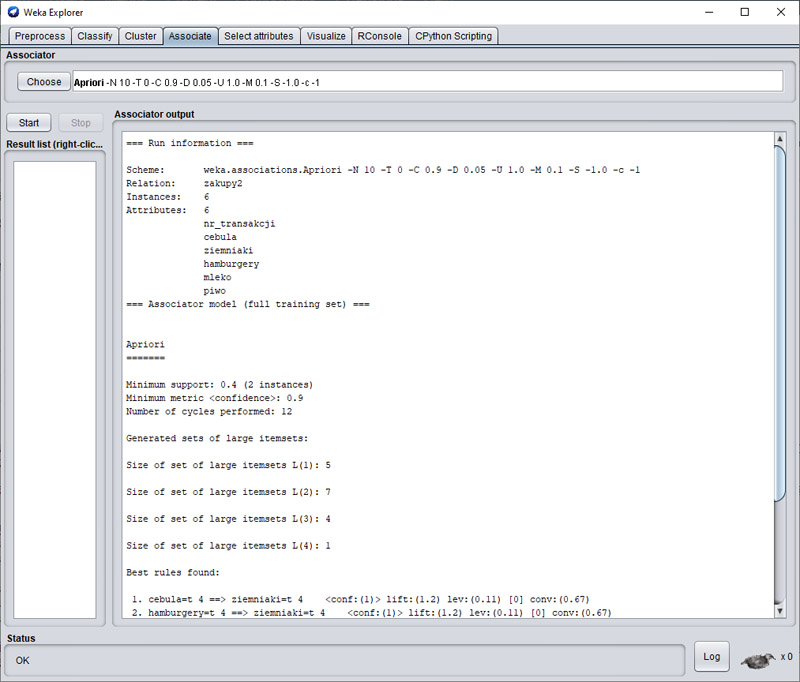
Najważniejsza część rezultatu działania tego algorytmu to sekcja "Best rules found". Mamy tutaj:
Best rules found:
1. cebula=t 4 ==> ziemniaki=t 4 <conf:(1)> lift:(1.2) lev:(0.11) [0] conv:(0.67)
2. hamburgery=t 4 ==> ziemniaki=t 4 <conf:(1)> lift:(1.2) lev:(0.11) [0] conv:(0.67)
3. cebula=t hamburgery=t 3 ==> ziemniaki=t 3 <conf:(1)> lift:(1.2) lev:(0.08) [0] conv:(0.5)
4. ziemniaki=t piwo=t 2 ==> cebula=t 2 <conf:(1)> lift:(1.5) lev:(0.11) [0] conv:(0.67)
5. cebula=t piwo=t 2 ==> ziemniaki=t 2 <conf:(1)> lift:(1.2) lev:(0.06) [0] conv:(0.33)
6. hamburgery=t piwo=t 2 ==> cebula=t 2 <conf:(1)> lift:(1.5) lev:(0.11) [0] conv:(0.67)
7. cebula=t piwo=t 2 ==> hamburgery=t 2 <conf:(1)> lift:(1.5) lev:(0.11) [0] conv:(0.67)
8. hamburgery=t piwo=t 2 ==> ziemniaki=t 2 <conf:(1)> lift:(1.2) lev:(0.06) [0] conv:(0.33)
9. ziemniaki=t piwo=t 2 ==> hamburgery=t 2 <conf:(1)> lift:(1.5) lev:(0.11) [0] conv:(0.67)
10. ziemniaki=t hamburgery=t piwo=t 2 ==> cebula=t 2 <conf:(1)> lift:(1.5) lev:(0.11) [0] conv:(0.67)
Jak interpretować wyniki? Przejdźmy przez podstawowe pojęcia:
Instancje
Instancje (instances) to wiersze/rekordy w danych źródłowych. W tym przykładzie plik ma 6 instancji.
Atrybuty
Atrybuty (attributes) to nazwy kolumn. Tutaj nazwy produktów. W pliku mamy atrybuty "cebula", "ziemniaki", "hamburgery"... Algorytm apriori akceptuje tylko wartości nominalne (tekst). Jeśli chcesz użyć liczbowych, musisz dokonać konwersji używając filtra "discretization".
Support
Algorytm apriori używa trzech typów zmiennych "support": „antecedent support”, „consequent support” i „support”. "Antecedent support'' oblicza odsetek transakcji, które zawierają itemset A, a „consequent support” oblicza wsparcie dla itemset C (consequent itemset). W Weka „antecedent support” wyrażony jest liczbą rekordów w źródle/bazie które zawierają itemset (w przypadku poniżej te koszyki które mają zarówno cebulę jak i hamburgery). Weka nie pokazuje liczby „consequent support” - byłaby to po prostu liczba rekordów w źródle zawierajacych ziemniaki.
Metryka "support" prezentuje wsparcie dla połączonego zestawu pozycji A ∪ C (czyli ile wspolnych rekordów mają A i C... ile razy tam gdzie sa cebula i hamburgery są także ziemniaki... ilosc wspólnych dla A (gdzie A to lewa strona i C (gdzie C to prawa strona)).
Czyli wsparcie ("support") dla linii uzyskujemy ze wzoru:
support (linii) = A ∪ C
Cofidence
Zaufanie ("cofidence") danej reguły/linii obliczamy dzieląc wsparcie dla linii ("support" linii) przez "atecedent support". Czyli w poniższym przykładzie 3 (obok ziemniaków) przez 3 (obok cebuli i hamburgerów). Wynik jest ułamkiem. W tym przypadku 1 oznacza 100%.
support(A→C)=support(A∪C)

Lift
Wskaźnik wzrostu ("lift") jest używany do określenia prawdopodobieństwo zakupu przedmiotu Y po zakupie przedmiotu X, kontrolując jednocześnie popularność przedmiotu Y. Dla przykładu warość 1 oznacza brak związku między przedmiotami. Wartość wzrostu większa niż 1 oznacza, że przedmiot Y prawdopodobnie zostanie kupiony, jeśli zostanie kupiony przedmiot X, podczas gdy wartość mniejsza niż 1 oznacza, że przedmiot Y prawdopodobnie nie zostanie kupiony, jeśli zostanie kupiony przedmiot X. Lift wyliczamy wg wzoru:
lift = confidence ("zaufanie") reguły / (support consequent itemset/liczba instancji... liczba rekordów w bazie)
Czyli dla pierwszej reguły (cebula=t 4 ==> ziemniaki=t 4), liczba lift zostanie wyliczona w następujący sposób:
Zaufanie wynosi tam 1. Support consequent itemset to 5 (jest pięć instancji z ziemniakami). Liczba instancji to 6 (mamy sześć rekordów w źródle). Czyli 1/(5/6) = 1.2
Laverage
Dźwignia oblicza różnicę między obserwowaną częstotliwością występowania A i C razem, a częstotliwością, której można by oczekiwać, gdyby A i C były niezależne. Wartość dźwigni równa 0 oznacza niezależność. Wzór:
laverage = support - support A x support C
Conviction
Wysoka wartość przekonania oznacza, że następnik w dużym stopniu zależy od poprzednika. Na przykład w przypadku doskonałego poziomu ufności mianownik przyjmuje wartość 0 (ze względu na 1 - 1), dla którego wynik skazania określa się jako „inf”. Podobnie jak w przypadku "lift", jeśli przedmioty są niezależne, przekonanie wynosi 1. Wzór:
przekonanie = support C / cofidence
Objaśnienie wyniku pracy algorytmu
W oknie z rezultatem pracy, po wciśnięciu przycisku "Start" zobaczymy rezultat:
=== Run information ===
Scheme: weka.associations.Apriori -N 10 -T 0 -C 0.9 -D 0.05 -U 1.0 -M 0.1 -S -1.0 -c -1
Relation: zakupy2-weka.filters.unsupervised.attribute.Remove-R1
Instances: 6
Attributes: 5
cebula
ziemniaki
hamburgery
mleko
piwo
=== Associator model (full training set) ===
Oznacza to że Weka przetworzyła "6 Instances" czyli 6 wierszy/rekordów z pliku. "Attributes 5" to liczba kolumn, atrybutów. Oczywiste. Następnie:
Minimum support: 0.4 (2 instances)
Minimum metric <confidence>: 0.9
Number of cycles performed: 12
Generated sets of large itemsets:
Size of set of large itemsets L(1): 5
Size of set of large itemsets L(2): 7
Size of set of large itemsets L(3): 4
Size of set of large itemsets L(4): 1
"Minimum support: 0.4" oznacza że ustawienia algorytmu były takie że do wyliczeń wzieliśmy rekordy które wystąpiły w co najmniej 40% wielkości naszej bazy. "Size of set of large itemsest L(x)" to ilość pojedyńczych itemsets (ilość artykułów w naszym przypadku)... pojawią się tylko wtedy jeśli proporcjonalnie do "Minimum support" wystąpią w pliku. Następnie podwojnych itemstest, potrojnych itemsets...itd. Uwaga, nie oznacza to że tyle z nich pojawi się w regułach wyświetlonych w wyniku przetworzenia. To np. zależy od ustawień ile reguł ma być prezentowanych przez program.
Best rules found:
1. cebula=t 4 ==> ziemniaki=t 4 <conf:(1)> lift:(1.2) lev:(0.11) [0] conv:(0.67)
2. hamburgery=t 4 ==> ziemniaki=t 4 <conf:(1)> lift:(1.2) lev:(0.11) [0] conv:(0.67)
3. cebula=t hamburgery=t 3 ==> ziemniaki=t 3 <conf:(1)> lift:(1.2) lev:(0.08) [0] conv:(0.5)
Tutaj mamy najlepsze reguły zaprezentowane przez algorytm. Jak interpretować te linie objaśniliśmy wyżej.
W danych znaleziono 10 reguł (domyślne ustawienia programu). Rezultat możesz zapisać klikając prawym przyciskiem na rezultat w oknie "Result list" i wybierajac "Save result buffer". Niestety, forma jest trudna do automatyczneo przetworzenia. Możemy jednak użyć innego narzędzia do znalezienia reguł w naszych danych, np. Python.
Alorytm apriori w biznesie
Retail: algorytm ten jest czasami nazywany analizą koszyka rynkowego. Jest używany w wielu sklepach detalicznych do odkrywania przydatnych informacji na temat zachowania klientów i ich transakcji. Te spostrzeżenia można wykorzystać do podejmowania strategicznych decyzji w celu zwiększenia sprzedaży i przyciągnięcia większej liczby klientów.
Systemy rekomendujące: systemy rekomendujące wykorzystują techniki, takie jak collaborative filtering i content based filtering w celu zarekomendowania nowych produktów użytkownikom e-sklepów. Dane historyczne zebrane na temat poprzednich użytkowników mogą zostać wykorzystane do stworzenia reguł asocjacji.
Marketing: algorytm apriori baradzo dobrze sprawdzi się w tworzeniu personalizowanych treści marketingowych. Np. e-mailing z ofertą do klientów. Jeden ze scenariuszy; wiedząc jakimi produktami lub jakimi grupami produktówch chcemy zainteresować klientów dzięki apriori możemy znaleźć klientów ktorzy będą tą ofertą zaintersowani.