
Grupowanie klientów wg reakcji na kanał przekazu marketingowego
Grupowanie to podział zbioru na grupy (klastry) bazujący na podobieństwach między nimi. W tym artykule dokonamy alnalizy reakcji klientów na kampanie marketinowego i podzielimy ich na grupy w zależności od tego na jaki przekaz reagują pozytywnie. Mając cechy klastra (spis kanałów gdzie klienci reagują pozytywnym oddzewem) i informację do którego klastra przynależy klient, możemy np. dostosować przyszly kanał kampanii marketingowych do preferencji klienta.
Konfigurujemy środowisko Python dołączając niezbędne biblioteki
Zaczynamy od importu bibliotek które będą nam potrzebne do wykonania zadania. Python jest na tyle sprytny że jeśli nie masz tych bibliotek w swoim środowisku, uzyskasz jasną podpowiedź co musisz zainstalować. Jeszcze jedno. Poleceń jest trochę. Użyj Jupyter Notebook by zorganizować je w jeden skrypt.
Odczyt i łączenie plików (a z nich skoroszytów) Excela dokonamy za pomocą biblioteki Pandas:
from pandas import read_excel, merge
Następnie dołączamy bibliotekę algorytmu "KMeans"
from sklearn.cluster import KMeans
Biblioteka "PCA" zapewni nam "liniową redukcja wymiarowości za pomocą dekompozycji danych na podstawie wartości w celu rzutowania ich na przestrzeń" czyli z matrycy zawierajacej dane liczbowe uzyskamy koordynaty dla osi X i Y.
from sklearn.decomposition import PCA
Potrzebujemy Plotly do wizualizacji danych klastrów (opcjonalnie):
import plotly.graph_objs as go
from plotly.offline import init_notebook_mode, iplot
init_notebook_mode()
Łączymy pliki Excela w jeden dataframe
Informacje o kampaniach przechowujemy w pliku "campaigns.xlsx" (skoroszyt 1), informacje o reakcjach w "reactions.xlsx"
df_campaign = read_excel("C:/Python/data/campaigns.xlsx", sheet_name = 0)
df_response = read_excel("C:/Python/data/reactions.xlsx", sheet_name = 0)
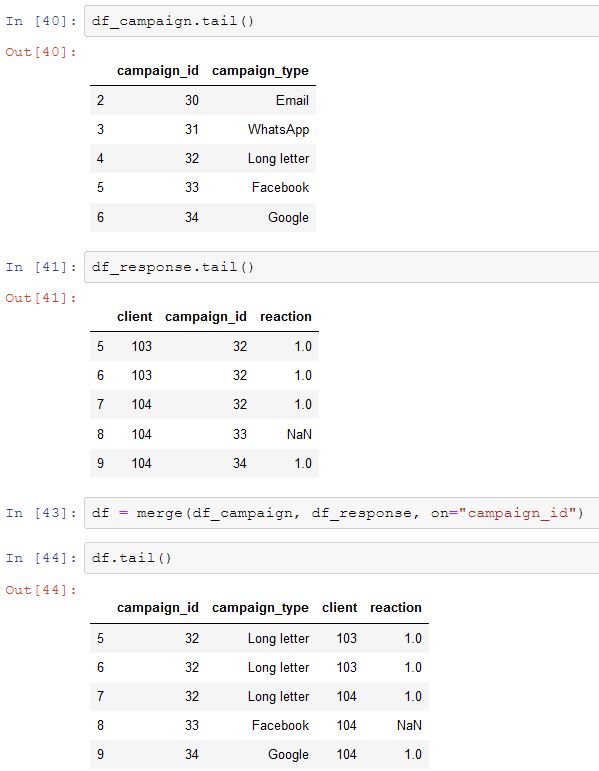
df_campaign.tail()
df_response.tail()
df = merge(df_campaign, df_response, on="campaign_id")
df.tail(
Odczytaliśmy zawartość plików, połączyliśmy je w jeden dataset a następnie wyświetliliśmy ostatnie n linii. Oto rezultat:
Następnie piwotujemy tabelę i sprawdzamy rezultat tej operacji:
table = df.pivot_table(index=["client"], columns=["campaign_id"], values="reaction")
table.tail()
Piwotujemy tabelę z danymi
Kolummy kampanii z polami reakcji klientów uzyskały wartości "1" lub "NaN" gdzie było brak danych. My potrzebujemy format "1.0" lub "0.0":
table =table.fillna(0).reset_index()
table.tail(
Pobieramy indeks kolumn który będzie nam potrzebny do określenia zakresu skąd wyliczymy dwuwymiarową mapę koordynatów X i Y
cols = table.columns[1:]
col
Tworzymy klastry algorytmem K-means
OK, przechodzimy do utworzenia klastrów. Określamy ile chcemy uzyskać klastrów (dobierz stosowną liczbę do ilości danych) a w następnej linii wyliczamy klastry i dodajemy rezultat do tabeli w kolumnie "cluster":
cluster = KMeans(n_clusters = 3)
table["cluster"] = cluster.fit_predict(table[table.columns[1:]].astype(str))
table.tail()
W tej chwili mamy podzielonych klientów na klastry. Możemy zapisać rezultat do pliku CSV:
table.to_csv("C:/Python/data/clusters.csv")
Wizualizujemy dane
Oobliczamy teraz średnie i wariancjie każdej z cech obecnych w naszych danych: uzyskamy w ten sposób koordynaty dla osi X i Y. Fit_transform zwraca dane w postaci tablicy np:
array([[-1.38340578, -0.2935787 ],
[-2.22189802, 0.25133484]])
By więc uzyskać dwie kolumy, x i y, mamy kod w dwóch liniach ("table['x']" i "table['y']"). Pamiętacie indeks kolumn "cols" powyżej? Używamy go teraz do określenia zakresu. W wyniku wykonania tych linii "table" zyska dwie nowe kolumny:
pca = PCA(n_components = 2)
table['x'] = pca.fit_transform(table[cols])[:,0]
table['y'] = pca.fit_transform(table[cols])[:,1]
table = table.reset_index()
table.tail()
Następnie tworzymy zestaw danych składający się z kolumny "client", "x" i "y":
client_clusters = table[["client", "cluster", "x", "y"]]
client_clusters.tail()
Rysujemy rozproszony wykres:
trace0 = go.Scatter(x = client_clusters[client_clusters.cluster == 0]["x"],
y = client_clusters[client_clusters.cluster == 0]["y"],
name='Cluster 1',
mode='markers',
marker=dict(size=10,
color="rgba(15, 152, 05)",
line = dict(width = 1, color = "rgb(0,0,0)")))
trace1 = go.Scatter(x = client_clusters[client_clusters.cluster == 1]["x"],
y = client_clusters[client_clusters.cluster == 1]["y"],
name='Cluster 2',
mode='markers',
marker=dict(size=10,
color="rgba(180, 18, 180, 0.5)",
line = dict(width = 1, color = [0, 0, 10, 0, 0, 0])))
trace2 = go.Scatter(x = client_clusters[client_clusters.cluster == 2]["x"],
y = client_clusters[client_clusters.cluster == 2]["y"],
name='Cluster 3',
mode='markers',
marker=dict(size=10,
color="rgba(132, 132, 1132, 0.8)",
line = dict(width = 1, color = [0, 0, 10, 0, 0, 0])))
data = [trace0, trace1, trace2]
iplot(data)
Przykład wizualizacji: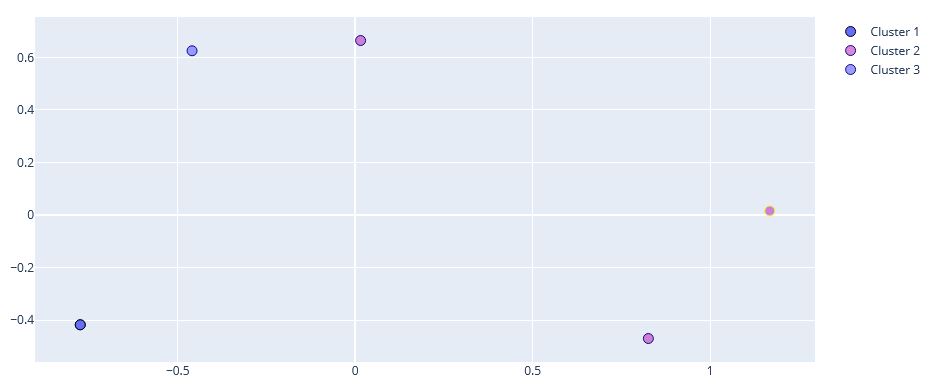
Jakie szczegóły zawieraja nasze klastry?
Łączymy dane "df_response", "client_clusters", "df_campaign" w jeden zestaw:
final = merge(df_response, client_clusters)
final = merge(df_campaign, final)
final.tail()
Zobaczmy co zawiera klaster nr 0 (1):
final["0"] = final.cluster == 0
final.groupby("0").campaign_type.value_counts()
Wynik tych komend to np:
Co oznacza że w tym klastrze klienci nie odpowiadają na "Letter, SMS, WhatsApp" a preferują "Letter, Long Letter". Jeśli chcesz sprawdzić jacy klienci znaleźli się w klastrze 0:
final[final.cluster == 0]["Client"]
Choć mamy te dane już w rezultacie, pliku CSV.
Gotowe - w ten sposób dopasujesz kanały marketingowe do preferencji klientów.
[artykuł inspirowany tutorialem Juan Klopper]