
Zastosowanie algorytmu klasyfikacji w uczeniu maszynowym
W dzisiejszym artykule nauczymy się stosować algorytm klasyfikacji używany w technikach "data mining" lub "eksploracji danych". Algorytm ten jest często stosowany w obszarze "uczenia maszynowego" a ta z kolei jest podzbiorem tak zwanej, z dużą przesadą, "sztucznej inteligencji".
Uczenie maszynowe (ML) jest nauka o algorytmach komputerowych. W skrócie; to po prostu jeden z algorytmów stworzonych przez człowieka który dzięki zastosowaniu dzisiejszych, wydajnych komputerów może wykonać zadanie szybko (lub lepiej powiedzieć może je w ogóle wykonąć). Magia rozwiązywania skomplikowanych zadań poprzez zastosowanie łańcucha funkcji i algorytmów.
W wielu miejscach spotkacie się z przekazem że "algorytmy się uczą". Nic podobnego - algorytm nigdy niczego sie nie "uczy". Algorytm to zestaw instrukcji jak wykonać daną pracę. Pozostaje taki sam cały czas - chyba że twórca go zmieni. Algorytmy w wyniku swojej pracy tworzą często na podstawie wzorcowych danych szablon jak należy traktować dane które nie wiemy jak zinterpretować. To jest nazywane często "uczeniem". Patrz rodział "Weka i algorytm J48".
Klasyfikacja - algorytm eksploracji danych
Klasyfikacja to przypisanie obiektu do określonej klasy na podstawie jego podobieństwa do poprzednich przykładów innych obiektów. Zazwyczaj klasy wzajemnie się wykluczają.
Przykładowym pytaniem klasyfikacyjnym byłoby „Którzy z naszych klientów odpowiedzą na naszą ofertę” i stworzenie dwóch klas:
„zareagują na ofertę”
oraz
„odrzucą ofertę”.
Inny przykładowy model klasyfikacji - ryzyko kredytowe. Mogłoby zostać opracowane na podstawie obserwowanych danych dla wnioskodawców kredytowych w pewnym okresie czasu. Możemy śledzić historię zatrudnienia, posiadanie domu lub wynajem, długość zamieszkania, rodzaj inwestycji i tak dalej. Docelowymi klasami byłby rating kredytowy; np. „niski” i „wysoki”.
Atrybuty (np. historia zatrudnienia) nazwiemy mądrze „predyktorami” (albo „zmiennymi niezależnymi”) a docelowe zmienne „zmiennymi zależnymi” lub po prostu „klasami”. Klasyfikacja należy do "nadzorowanych" metod. Czym są metody nadzorowane czytaj w „Metody nadzorowane i metody nienadzorowane" poniżej.
Weka i algorytm J48
„Którzy klienci mogą opuścić nas w najbliższym czasie?”
Algorytmem który możemy zastosować do próby znalezienia odpowiedzi na to pytanie jest np J48. Następca C4.5, którego poprzednikiem jest ID3. Algorytm wykorzystuje koncepcję entropii czyli w skrócie „ile pytań niezbędnych jest by dotrzeć do informacji?”. Algorytm ten należy do grupy algorytmów „drzewa decyzyjnego”. Jest co najmniej 835463248965 artykułów w Internecie o tych algorytmach i drzewach decyzyjnych…. z czego 2/4 napisana przez tych którzy nie wiedzą sami jak one działają i 1/4 przez naukowców, którzy skupili się na zakodowaniu informacji.
By spróbować odpowiedzieć na pytanie, którzy klienci mogą odejść, potrzebować będziemy danych historycznych jako wzoru zachowań (gdzie wiemy, którzy klienci nas opuścili a którzy nie). Analizując te informacje, atrybuty, utworzymy model na podstawie którego przeanalizujemy dane klientów, którzy są jeszcze naszymi klientami (dane obecne). Ostatnia kolumna w tabeli poniżej to klasa (odpowiedź której będziemy szukać w danych).
Programam który użyjemy by dokonąc klasyfikacji to Weka - oprogramowanie zostało stworzone w Nowej Zelandii na uniwersytecie Waikato. Pobierz wiec program i zainstaluj na swoim komputerze.
OK, w naszym ćwiczeniu mamy dane historyczne klientów o których wiemy że nas opuścili (kolumna 'stracony'). Dla tych klientów may takie atrybuty jak wysokosc obrotów, ilosć artykułów które kupili, częstotliwość zamówień. To tylko przykład - Ty możesz mieć inne. Użyjemy tych danych do "wytrenowania" naszego modelu.

Trenowanie modelu to budowanie wzorca, szablonu wgo którego będziemy następnie starali się odgadnąć zachowania obecnych klientów (o których jeszcze nie wiemy czy odeszli czy nie). My, ludzie, też tak działamy (a przecież algorytm został wymyślony przez ludzi nie obcych z kosmosu). Wyobraź sobie że na podstawie zachowań kierowców próbujesz podzielic ich na klasy; tych którzy nie będą mieć wypadku i tych ktorzy z dużym prawdopodobieństwem wcześniej czy później w coś wyrąbią. Patrzysz więc na danego osobnika i zadajesz, sobie, pytania: czy przekracza nadmiernie prędkość? czy skacze po pasach w intensywnym ruchu? czy przejezdza na czerwonych światłach? czy nie zachowuje bezpiecznych odstępów? ...i tak dalej.
Klasyfikujemy klientów w Weka - wczytaj atrybuty
Po uruchomieniu programu pojawi się nam okno startowe:

W sekcji "Applications" wybieramy pierwszą pozycję, Explorer. W oknie ktore pojawi się na ekranie, wybieramy plik z historią naszych klientów - "open file". Domyślnym separatorem w Weka jest przecinek. Możesz zmienić znak separatora zaznaczając checkbox "Invoke options dialog" w oknie dialogowym otwarcia pliku CSV.

Usuwanie zbędnych atrybutów
Po otwarciu pliku w sekcji "Attributes" zobaczysz wszystkie kolumny wczytane z pliku. Gdybyśmy chcieli usunąć jakiś atrybut z zestawu (nie uwuwaj żadnego atrybutu w tej chwili - to tylko dla Twojej wiedzy) możemy zrobić to na dwa sposóby.
Pierwszy to wybranie to po prostu zaznaczenie atrybutu który chcemy usunąć i kliknięcie na przycisk "Remove" pod listą atrybutów. Drugi sposób to użycie filtrów Weki. Aby zastosować filter usuwający atrybuty klikamy na "Choose" w sekcji "Filter". Następnie wybieramy:
Weka => Filters => unsupervised => attribute => Remove
Po wybraniu filtra, ustawiamy jego parametry. Musimy zadecydować który atrybut ma zostać usunięty. Klikamy na nazwę wybranego filtra, "Remove" i w polu "attributeindices" wpisujemy nr atrybutu (patrz na głowne okno i listę atrybutów). Mozesz usunąć jeden lub wiele atrybutów. Możesz tez odwrócić selekcje - usun wszystkie poza wybranym.
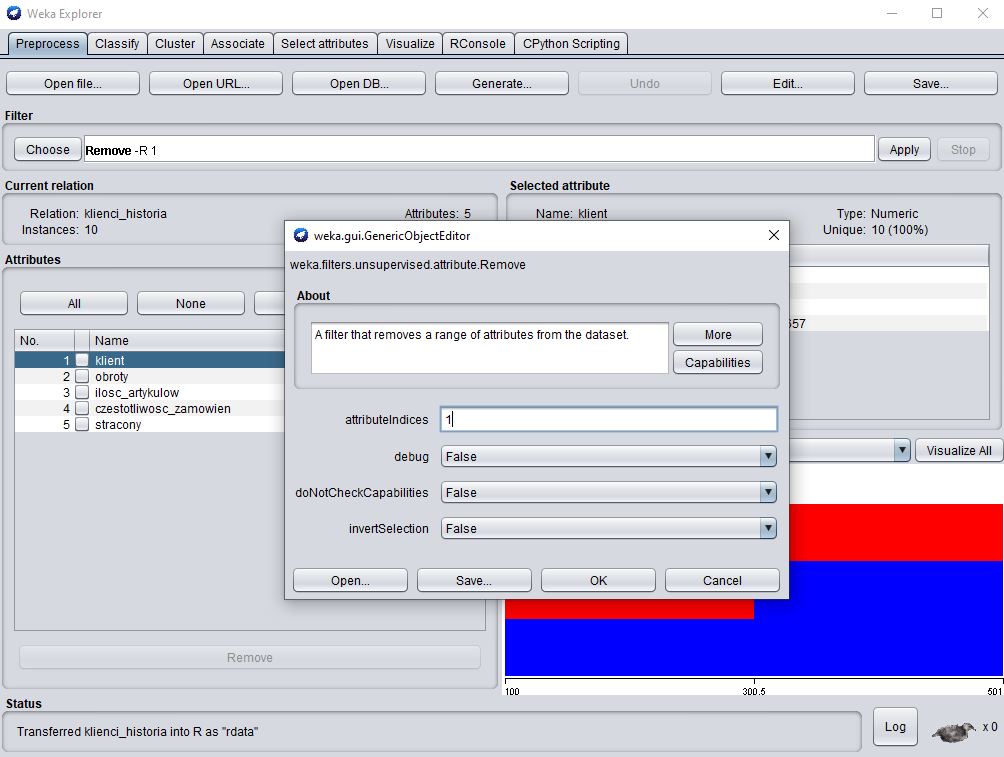
Po wpisaniu numeru atrybuty klikamy na OK. Filter nie zostanie wykonany do czasu kliknięcia na przycisk "Apply" obok nazwy atrybutu. Klinij i zobacz ze atrybut "klient" został usunięty z listy. Więcej o stosowaniu filtrów dowiesz się z tego video.
Klasyfikujemy klientów w Weka - ustawianie klasyfikatora
Następnym krokiem jest wybrani typu klasyfikatora. My użyjemy algorytmu J48. Wybieramy zakładkę "Classify" i w sekcji "Classifier" klikamy na "choose". Wybieramy:
Weka => classifiers => trees => J48
Możemy ustawić parametry tego algorytmu klikajac na nazwę klasyfikatora. Nie będziemy tego robić w tym ćwiczeniu - użyjemy standardowych ustawień.
Wyłączenie zbędnych atrybutów z procesu klasyfikacji
Nasze dane zawierają atrybut "klient". Jest to ID klienta. Nie chcemy brać tego atrybutu pod uwagę w procesie - tak uzyskane wyniki byłyby nieprawdziwe. Musimy wiec usunąć ten atrybut. Z drugiej strony jak bedziemy wiedzieć ktory rekord dotyczy którego klienta po podstawieniu produkcyjnych danych? Rozwiązaniem jest zastosowanie filtra który usunie atrybut z zestawy tylko podczas procesu budowania modelu.
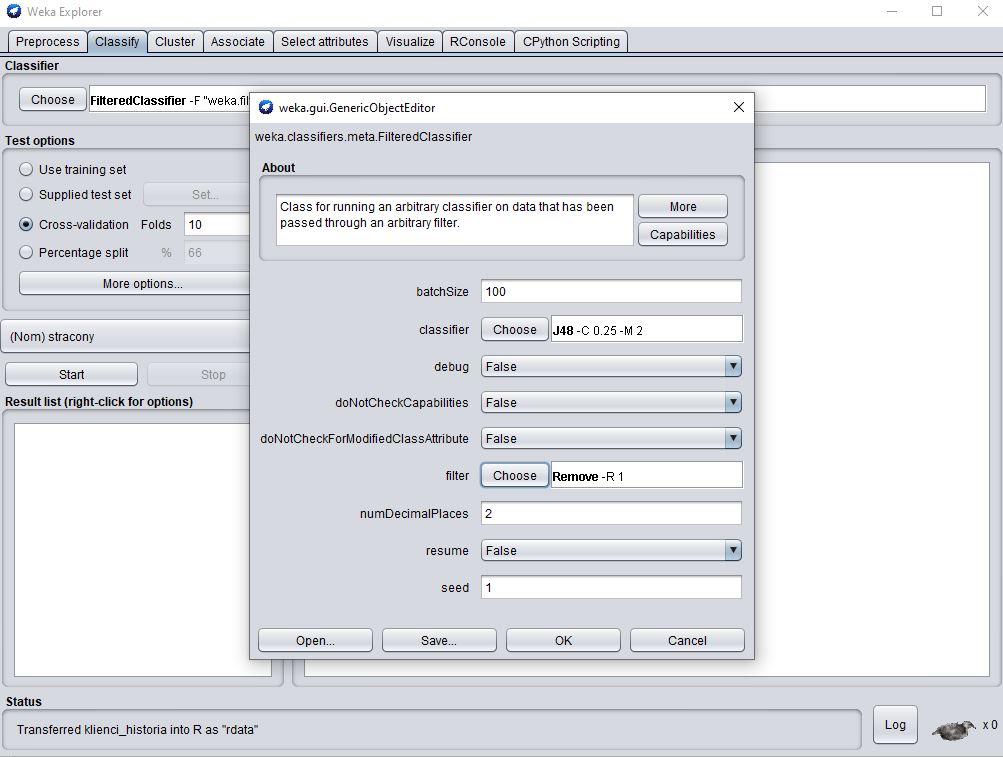
W tabeli "Classify" wybierz "choose" w sekcji "Classifier". A następnie:
meta => FilteredClassifier
W rezultacie w polu wyboru klasyfikatora pojawią się parametry rozpoczynające się od "FilteredClassifier -F". Kliknij na to wyrażenie a następnie wybierz:
Filter => choose => unsupervised => attributes => Remove
Następnie klinij na słowo "Remove" które pojawiło się w polu "filter". W polu "attributeIndices" wpisz numer lub numery atrybutów które chcesz usunąć z przetwarzania.
Klasyfikujemy klientów w Weka - budujemy model
OK, klikamy na przycisk "Start". W efekcie w oknie "Classifier output" pojawi się rezultat pracy algorytmu. W sekcji result list (lewy dół ekranu) mamy link do zapisu tego uruchomienia (możesz testować uruchomienia z różnymi ustawieniami - każde uruchomienie doda nowy rezultat w tym oknie do którego możesz wrócić po kliknięciu na pozycję). Zapoznaj się też z wideo demonstrującym tę opcję.
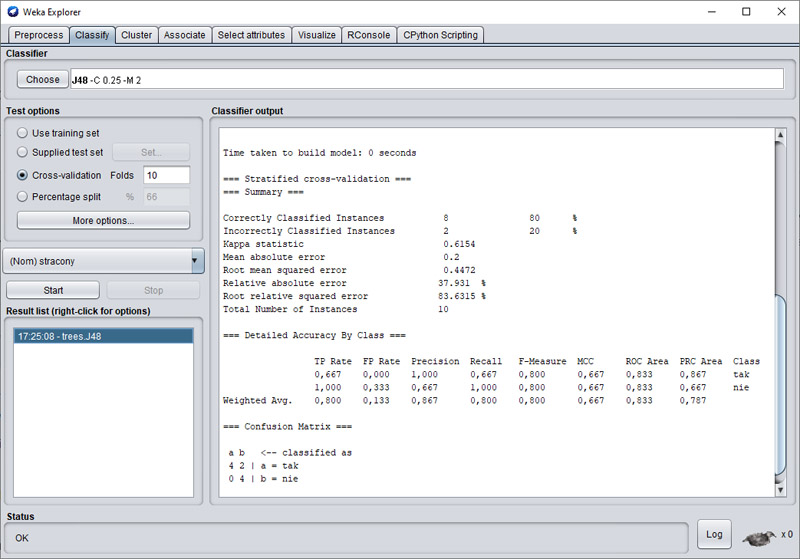
Jak widzimy w rezultacie precyzja wyniosła 80%. Nieźle. Możesz testować różne ustawienia zwiększając/zmniejszając precyzję.
OK, użyjmy zatem tego rezultatu jako naszego modelu do analizy bieżących danych - będzie to nasz szablon wg którego ocenimy klientów co do których nie wiemy czy odejdą czy nie. Rezultat zapiszmy jako model: kliknij prawym przyciskiem myszy na rezultat (sekcja "Result list") i wybierz "save model".
Klasyfikujemy klientów w Weka - przewidujemy zachowanie naszych obecnych klientów
Nasza dotychczasowa praca byłaby bezużyteczna jeśli wykonalibyśmy tylko klasyfikację danych historycznych (jak demonstruje to wieszość tutoriali w Internecie). Chcemy przecież dokonać prognozy zachowań naszych klientów - odgadnąć ich postępowanie w najbliższej przyszłości. Odejdą czy zostaną?
Wczytujemy gotowy model
We wcześniejszych kroku zapisaliśmy nasz model. Teraz użyjemy go by stworzyć prognozę danych bieżących. Nasze dane, plik csv, powinny mieć taką samą strukturę. Ostania jednak kolumna powinna zamiast "tak" lub "nie" mieć znak zapytania; "?". Przygotuj w takim formacie testowe dane a następnie w zakladce "Classify", w oknie "Result list" kliknij prawym przyciskiem myszy i wybierz pozycje "Load model". Jeśli wczytywanie modelu wykonujesz zaraz po uruchomieniu programu zakładka "Classify" jest nieaktywna. Wczytaj dowolny plik w pierwszej zakladce by odblokować zakładkę "Classify" (jaki to będzie plik, nie ma znaczenia - będziemy pracować na wcześniej zdefiniowanym modelu).
OK, wybierz model i kliknij na "open". W efekcie w polu "Result list" pojawił się nasz model. Dokonaj teraz ustawień opcji - w jakiej formie zobaczysz rezultat. Domyślnie rezultat przetwarzania zobaczysz w oknie, po prawej stronie ekranu. Nas interesują wyniki w formie do dalszego przetwarzania - pliku tekstowym. Kliknij na "More options" i wybierz w polu "output predictions "CSV". Następnie kliknij na "CSV". Oczywiście wskaż w polu "outputFile" gdzie chesz zapisać plik z wynikami.
Pamiętasz że usuwaliśmy pole/atrybut "klient" z naszego modelu. Chcielibyśmy jednak po klasyfikacji danych i zbudowaniu prognozy mieć ID klienta - inaczej nie będziemy w stanie przypasować predykcji do rekordów klientów. W polu "attributes" wpisz numery kolumn które powinny pojawić się ekstra w wyniku, np. "1". Potwierdz zmiany; "OK" i ponownie "OK".
Wybieramy nasz plik z bieżącymi danymi klientów (ten z "?" w kolumnie "stracony") wybierajac "Set" obok "Supplied test set". Domyślnie naszą klasą powinien być atrybut "stracony". Finalizujemy naszą pracę. Kliknij prawym przyciskiem myszy na nazwę naszego modelu w oknie "Result list" i wybierz "Re-evaluate model on current test set". Gotowe! Twój plik CSV zawiera rezultat "predykcji" zachowań klientów.
Metody nadzorowane i metody nienadzorowane
Inaczej uczenie nadzorowane i uczenie nienadzorowane. W uczeniu nadzorowanym stawiamy konkretny cel – spodziewamy się określonego wyniku. Na przykład:
„Czy możemy znaleźć grupy klientów, którzy mają szczególnie wysokie prawdopodobieństwo anulowania ich usługi wkrótce po wygaśnięciu ich umów? ” Albo:
„Podzielmy klientów ze względu na ryzyko niewypłacalności; małe, średnie, duże.”
Przykłady metod nadzorowanych to klasyfikacja i regresja. Używane tutaj często algorytmy to decision tree, logistic regression, random forest, support vector machine, K-nearest neighbors.
W uczeniu nienadzorowanym nie stawiamy sobie konkretnego celu – nie spodziewamy się określonego wyniku docelowego. Stawiane tutaj pytania to np:
„Czy nasi klienci tworzą różne grupy?”
Przykłady metod nienadzorowanych to grupowanie (clustering) i korelacja (association)
W przenośni nauczyciel „nadzoruje” ucznia starannie dostarczając informacje o celu wraz z zestawem przykładów. Nienadzorowane zadanie edukacyjne może obejmować ten sam zestaw ćwiczeń ale nie zawiera informacji o celu - uczący się nie otrzyma informacji o celu nauki ale ma sformułować własne wnioski z informacji, które otrzymał.